Linux Kernel Netfilter
해당 포스트에서는 리눅스 커널의 넷필터에 대해 설명합니다.
넷필터 서브시스템은 네트워크 스택 내에서 패킷이 이동하는 여러 지점에 콜백을 등록하는 것을 비롯해 주소나 포트 변경, 패킷 drop, 로깅 등과 같이 패킷 상의 다양한 동작을 수행할 수 있는 프레임워크를 제공합니다.
넷필터 프레임워크
넷필터 서브시스템이 수행할 수 있는 기능의 예시는 다음과 같다.
- 패킷 선택 및 필터링 (iptables)
- 네트워크 주소 변환 (NAT)
- 패킷 맹글링(Mangling; 라우팅 전후로 패킷 헤더의 내용을 수정)
- 연결 추적
- 네트워크 통계 수집
리눅스 커널 넷필터 서브시스템을 기반으로 한 프레임워크 대표 예시는 다음과 같다.
- iptables : 넷필터에 대한 관리 계층을 제공하는 유저 스페이스 프레임워크로, 넷필터 규칙의 추가와 삭제, 통계 표시, 테이블 추가, 테이블 카운터 초기화 등의 기능이 있다.
- IPVS : transport 계층의 로드밸런싱 기능(Layer 4 LAN Switching)을 제공하는 IP 가상 서버 솔루션이다.
- IPSet : ipset 유틸리티로 IP 주소, 포트 주소, MAC 주소, 인터페이스 이름 등을 저장할 수 있는 기능을 제공하는 프레임워크다.
넷필터 훅
네트워크 스택에는 넷필터 훅을 등록할 수 있는 다섯 개의 지점이 있다.
다섯 개의 훅의 이름은 다음과 같다.
- NF_INET_PRE_ROUTING :
ip_rcv()함수와ipv6_rcv()함수에 있다. 라우팅 서브시스템 탐색을 수행하기 전 모든 수신 패킷이 도착하는 첫 번째 훅 지점이다. - NF_INET_LOCAL_IN :
ip_local_deliver()함수와ip6_input()함수에 있다. 로컬 호스트로 향하는 모든 수신 패킷은 라우팅 서브시스템 탐색을 수행한 후 이 훅 지점에 도착한다. - NF_INET_FORWARD :
ip_forward()함수와ip6_forward()함수에 있다. 포워딩 되는 모든 패킷은 라우팅 서브시스템 탐색을 수행한 후 이 훅 지점에 도착한다. - NF_INET_POST_ROUTING :
ip_output()함수와ip6_finish_output2()함수에 있다. 포워딩되거나 로컬호스트에서 생성되어 전송되는 모든 송신 패킷은 라우팅 서브시스템 탐색을 수행한 후 해당 지점에 도착한다. NF_INET_FORWARD/NF_INET_LOCAl_OUT 보다 후에 도착하는 지점이다. - NF_INET_LOCAL_OUT :
__ip_local_out()함수와__ip6_local_out()함수에 있다. 로컬 호스트에서 생성된 모든 송신 패킷이 도착하는 첫 번째 훅 지점이다.
넷필터 훅을 등록하는 매크로 NF_HOOK의 정의는 다음과 같다.
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb);
return ret;
}
/**
* nf_hook - call a netfilter hook
*
* Returns 1 if the hook has allowed the packet to pass. The function
* okfn must be invoked by the caller in this case. Any other return
* value indicates the packet has been consumed by the hook.
*/
static inline int nf_hook(u_int8_t pf, unsigned int hook, struct net *net,
struct sock *sk, struct sk_buff *skb,
struct net_device *indev, struct net_device *outdev,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
struct nf_hook_entries *hook_head = NULL;
int ret = 1;
#ifdef CONFIG_JUMP_LABEL
if (__builtin_constant_p(pf) &&
__builtin_constant_p(hook) &&
!static_key_false(&nf_hooks_needed[pf][hook]))
return 1;
#endif
rcu_read_lock();
switch (pf) {
case NFPROTO_IPV4:
hook_head = rcu_dereference(net->nf.hooks_ipv4[hook]);
break;
case NFPROTO_IPV6:
hook_head = rcu_dereference(net->nf.hooks_ipv6[hook]);
break;
case NFPROTO_ARP:
#ifdef CONFIG_NETFILTER_FAMILY_ARP
if (WARN_ON_ONCE(hook >= ARRAY_SIZE(net->nf.hooks_arp)))
break;
hook_head = rcu_dereference(net->nf.hooks_arp[hook]);
#endif
break;
case NFPROTO_BRIDGE:
#ifdef CONFIG_NETFILTER_FAMILY_BRIDGE
hook_head = rcu_dereference(net->nf.hooks_bridge[hook]);
#endif
break;
#if IS_ENABLED(CONFIG_DECNET)
case NFPROTO_DECNET:
hook_head = rcu_dereference(net->nf.hooks_decnet[hook]);
break;
#endif
default:
WARN_ON_ONCE(1);
break;
}
if (hook_head) {
struct nf_hook_state state;
nf_hook_state_init(&state, hook, pf, indev, outdev,
sk, net, okfn);
ret = nf_hook_slow(skb, &state, hook_head, 0);
}
rcu_read_unlock();
return ret;
}
NF_HOOK() 매크로의 매개변수는 다음과 같다.
- pf : 프로토콜 패밀리
- hook : 위에서 언급한 후킹 값 중 하나이다. (NF_INET_PRE_ROUTING 등)
- net : 네트워크 네임스페이스 객체
- sk : 소켓 객체
- skb : 처리 중인 패킷을 나타내는 SKB 객체
- in : 입력 네트워크 장치
- out : 출력 네트워크 장치
- okfn : 훅이 종료되면 호출될 함수 포인터
넷필터 훅의 반환 값은 다음 중 하나여야 한다.
- NF_DROP(0) : 패킷을 폐기한다.
- NF_ACCEPT(1) : 패킷이 커널 네트워크 스택에서 계속 이동한다.
- NF_STOLEN : 패킷은 훅 함수로 처리되어 이동하지 않는다.
- NF_QUEUE : 유저 스페이스 큐에 패킷을 넣는다.
- NF_REPEAT : 훅 함수가 다시 호출돼야 한다.
(그 외 NF_STOP 값은 deprecated 되었다.)
넷필터 훅 등록
넷필터 훅 콜백을 등록하려면 nf_hook_ops 객체 혹은 객체 배열을 정의한 후 등록해야 한다. 해당 구조체의 정의는 다음과 같다.
typedef unsigned int nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state);
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook;
struct net_device *dev;
void *priv;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
- hook : 등록하려는 훅 콜백
- pf : 프로토콜 패밀리 (NFPROTO_IPv4 등)
- hooknum : 다섯 가지 넷필터 훅 중 하나 (NF_INET_PRE_ROUTING 등)
- priority : 훅 콜백의 우선순위로, 낮은 훅 콜백이 먼저 호출된다.
넷필터 훅을 등록 및 해제하는 함수는 다음과 같다.
int nf_register_hook(struct nf_hook_ops *reg);: 하나의 넷필터 훅을 ops 객체로 등록한다.void nf_unregister_hook(struct nf_hook_ops *reg);: 등록한 넷필터 훅을 해제한다.int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n);: 여러 개의 넷필터 훅을 ops 객체 배열로 등록한다. 두 번째 매개변수는 배열의 요소 개수이다.void nf_unregister_hooks(struct nf_hook_ops *reg, unsigned int n);: 여러 개의 등록된 넷필터 훅을 해제한다. 두 번째 매개변수는 배열의 요소 개수이다.
Connection Tracking
FTP 또는 SIP와 같은 세션 기반 트래픽을 고려하여 커널은 연결 추적 기능을 제공한다.
연결 추적 계층의 주요 목적은 NAT의 기반 역할을 하는 것이다.
Connection Tracking 초기화
IPv4의 연결 추적 초기화를 위한 nf_hook_ops 객체의 배열은 다음과 같이 정의되어 있다.
/* Connection tracking may drop packets, but never alters them, so
* make it the first hook.
*/
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_confirm,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_confirm,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};
주요 후킹 함수는 NF_INET_PRE_ROUTING 후킹에서 처리되는 ipv4_conntrack_in() 함수와 NF_INET_LOCAL_OUT 후킹에서 처리되는 ipv4_conntrack_local() 함수이다.
위 두 함수의 우선순위 NF_IP_PRI_CONNTRACK(-200)는 다른 우선순위 NF_IP_PRI_CONNTRACK_CONFIRM(INT_MAX)보다 높다.
또한, 두 함수의 정의를 살펴보면 결국 nf_conntrack_in() 함수에 상응하는 hooknum을 전달하여 호출한다.
이러한 연결 추적 후킹 오퍼레이션 객체는 nf_ct_netns_do_get() 함수에서 등록한다.
다음 그림은 등록된 훅 지점에 따른 연결 추적 콜백 함수의 flow를 보여준다.
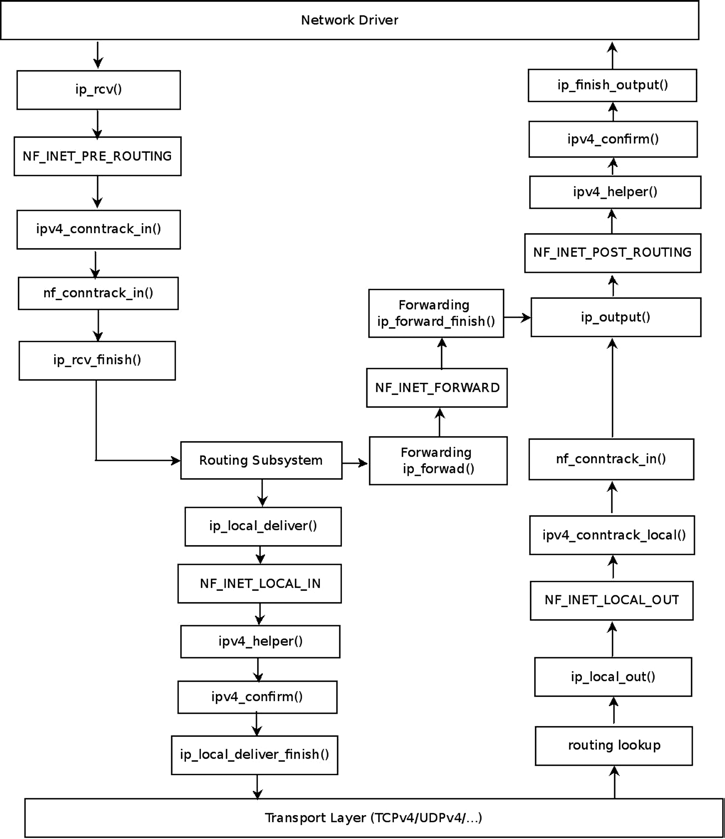
연결 추적 항목
연결 추적 기본 요소인 nf_conntrack_tuple 객체는 한 방향의 flow를 나타낸다.
/* This contains the information to distinguish a connection. */
struct nf_conntrack_tuple {
struct nf_conntrack_man src;
/* These are the parts of the tuple which are fixed. */
struct {
union nf_inet_addr u3;
union {
/* Add other protocols here. */
__be16 all;
struct {
__be16 port;
} tcp;
struct {
__be16 port;
} udp;
struct {
u_int8_t type, code;
} icmp;
struct {
__be16 port;
} dccp;
struct {
__be16 port;
} sctp;
struct {
__be16 key;
} gre;
} u;
/* The protocol. */
u_int8_t protonum;
/* The direction (for tuplehash) */
u_int8_t dir;
} dst;
};
연결 추적 항목을 나타내는 구조체 nf_conn의 정의는 다음과 같다.
struct nf_conn {
/* Usage count in here is 1 for hash table, 1 per skb,
* plus 1 for any connection(s) we are `master' for
*
* Hint, SKB address this struct and refcnt via skb->_nfct and
* helpers nf_conntrack_get() and nf_conntrack_put().
* Helper nf_ct_put() equals nf_conntrack_put() by dec refcnt,
* beware nf_ct_get() is different and don't inc refcnt.
*/
struct nf_conntrack ct_general;
spinlock_t lock;
/* jiffies32 when this ct is considered dead */
u32 timeout;
#ifdef CONFIG_NF_CONNTRACK_ZONES
struct nf_conntrack_zone zone;
#endif
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* Have we seen traffic both ways yet? (bitset) */
unsigned long status;
u16 cpu;
possible_net_t ct_net;
#if IS_ENABLED(CONFIG_NF_NAT)
struct hlist_node nat_bysource;
#endif
/* all members below initialized via memset */
struct { } __nfct_init_offset;
/* If we were expected by an expectation, this will be it */
struct nf_conn *master;
#if defined(CONFIG_NF_CONNTRACK_MARK)
u_int32_t mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
u_int32_t secmark;
#endif
/* Extensions */
struct nf_ct_ext *ext;
/* Storage reserved for other modules, must be the last member */
union nf_conntrack_proto proto;
};
- ct_general : 참조 카운터
- tuplehash : 연결 tuple에 대한 hash 배열이다.
tuplehash[IP_CT_DIR_ORIGINAL]는 원래 방향이고,tuplehash[IP_CT_DIR_REPLY]는 응답 방향이다. - status : 항목의 상태를 나타낸다. 연결 항목 추적을 시작하면 IP_CT_NEW가 되고, 연결이 성립되면 IP_CT_ESTABLISHED가 된다.
- master : 예상(expected) 연결. 예상 패킷이 도착하면
init_conntrack()함수로 설정한다. - timeout : 연결 항목의 타이머로, 각 연결 항목은 통신이 없으면 특정 시간 후 타이머가 만료된다.
이 전에 언급한 ipv4_conntrack_in() 함수와 ipv4_conntrack_local() 함수에서 호출하던 nf_conntrack_in() 함수 내용을 간단히 설명하면 다음과 같다.
tmpl = nf_ct_get(skb, &ctinfo);라인으로 추적 가능한지 확인하고, 연결 추적 정보 객체를 생성한다.dataoff = get_l4proto(skb, skb_network_offset(skb), state->pf, &protonum);라인으로 L4 계층이 추적 가능한지 확인한다.- ICMP 프로토콜을 처리한다.
ret = resolve_normal_ct(tmpl, skb, dataoff, protonum, state);라인으로 튜플의 해시를 계산 및 탐색을 수행하고, 일치하는 튜플을 찾지 못하면 새로운 해쉬 객체를 생성한다.ct = nf_ct_get(skb, &ctinfo);라인으로 SKB에 설정된 추적 정보를 얻는다.ret = nf_conntrack_handle_packet(ct, skb, dataoff, ctinfo, state);라인으로 프로토콜에 특화된 패킷 처리를 수행한다.
핵심이 되는 함수는 nf_conntrack_handle_packet() 함수이다.
Connection Tracking Helpers and Expectations
FTP나 SIP같은 프로토콜에서는 data flow와 control flow가 다르다.
넷필터 서브시스템은 이러한 프로토콜의 서로 관련된 flow를 인식하기 위하여 연결 추적 도우미를 제공한다.
이러한 모듈은 예상(nf_conntrack_expect) 객체를 생성하고, 이 예상은 지정된 연결에서 트래픽이 발생할 것이라는 것과 두 연결이 서로 관련되어 있다는 것을 말해준다.
두 연결이 관련돼 있다는 사실을 알면 관련된 연결에 속한 마스터 연결에 규칙을 정의할 수 있다.
예를 들어, 다음과 같이 iptables 규칙을 이용하여 연결 추적 상태가 RELATED인 패킷을 수락할 수 있다.
$ iptables -A INPUT -m conntrack --ctstate RELATED -j ACCEPT
연결 추적 헬퍼는 nf_conntrack_helper 구조체로 표현한다.
헬퍼 객체는 nf_conntrack_helper_register() 함수와 nf_conntrack_helper_unregister() 함수로 각각 등록/해제한다.
헬퍼 객체 배열은 nf_conntrack_helpers_register() 함수와 nf_conntrack_helpers_unregister() 함수로 각각 등록/해제한다.
예를 들어, nf_conntrack_ftp_init() 함수에서 FTP 연결 추적 헬퍼를 등록하기 위하여 nf_conntrack_helpers_register() 함수를 호출한다.
연결 추적 헬퍼는 해시 테이블에 유지된다.
nf_conntrack_helper 객체는 nf_ct_helper_init() 함수로 초기화되는데, 해당 과정에서 객체 멤버 help 함수 포인터에 헬퍼 함수를 등록한다.
FTP에 등록되는 help 함수는 링크와 같다.
해당 함수에서 exp = nf_ct_expect_alloc(ct); 함수와 nf_ct_expect_init() 함수를 호출하여 expectation 객체를 할당/초기화 한다.
나중에 nf_conntrack_in() 함수에서 resolve_normal_ct() -> init_conntrack() 함수를 호출하여 새로운 연결이 생성되면 이 연결에 예상 객체가 포함되어있는지 검사하고, 포함되어 있다면 IPS_EXPECTED_BIT 플래그를 설정하고 ct->master = exp->master; 라인으로 마스터 연결을 설정한다.
헬퍼는 사전에 정의된 포트를 리스닝한다. 예를 들어, FTP 헬퍼는 기본적으로 21번 포트를 리스닝하고, 다음 두 가지 방법으로 리스닝할 포트를 추가할 수 있다.
- modprobe 파라미터
modprobe nf_conntrack_ftp ports=2022,2023,2024
- iptables CT
iptables -A PREROUTING -t raw -p tcp --dport 8888 -j CT --helper ftp
IPTables
iptables는 /net/ipv[4,6]/netfilter 아래에 존재하는 핵심 커널 코드와, iptables 계층에 접근하기 위한 유저 스페이스 프론트엔드 부분으로 나눠진다.
각 테이블은 xt_table 구조체로 표현하며, ipt_register_table() 함수와 ipt_unregister_table_exit() 함수로 등록 및 해제한다.
실제 테이블 예시는 다음과 같다.
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \
(1 << NF_INET_FORWARD) | \
(1 << NF_INET_LOCAL_OUT))
static int __net_init iptable_filter_table_init(struct net *net);
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = FILTER_VALID_HOOKS,
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.priority = NF_IP_PRI_FILTER,
.table_init = iptable_filter_table_init,
};
static unsigned int
iptable_filter_hook(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
return ipt_do_table(skb, state, priv);
}
static struct nf_hook_ops *filter_ops __read_mostly;
static int __net_init iptable_filter_table_init(struct net *net)
{
struct ipt_replace *repl;
int err;
repl = ipt_alloc_initial_table(&packet_filter);
if (repl == NULL)
return -ENOMEM;
/* Entry 1 is the FORWARD hook */
((struct ipt_standard *)repl->entries)[1].target.verdict =
forward ? -NF_ACCEPT - 1 : -NF_DROP - 1;
err = ipt_register_table(net, &packet_filter, repl, filter_ops);
kfree(repl);
return err;
}
static int __init iptable_filter_init(void)
{
int ret;
filter_ops = xt_hook_ops_alloc(&packet_filter, iptable_filter_hook);
if (IS_ERR(filter_ops))
return PTR_ERR(filter_ops);
ret = register_pernet_subsys(&iptable_filter_net_ops);
if (ret < 0)
kfree(filter_ops);
return ret;
}
모듈 초기화 함수인 iptable_filter_init() 함수에서 테이블 및 오퍼레이션 등록 등의 초기화를 수행한다.
테이블 객체 packet_filter에서는 테이블 초기화 함수를 iptable_filter_table_init() 함수로 등록한다.
해당 초기화 함수에서 err = ipt_register_table(net, &packet_filter, repl, filter_ops); 라인으로 테이블을 등록한다.
필터 테이블에는 세 가지 훅이 있다.
- NF_INET_LOCAL_IN
- NF_INET_FORWARD
- NF_INET_LOCAL_OUT
필터 테이블 규칙을 통해 포워딩되는 트래픽의 flow는 다음과 같다.
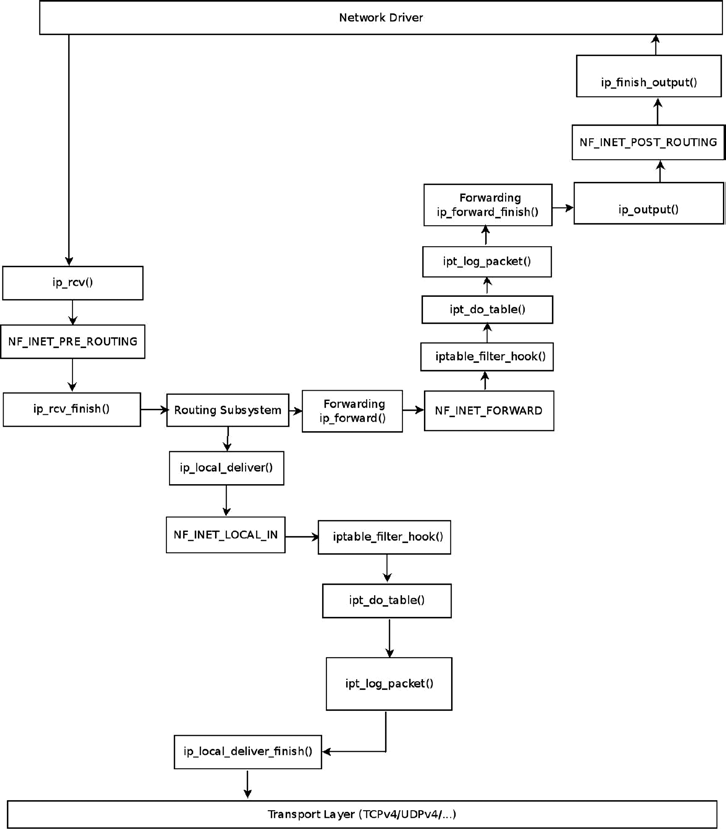
예를 들어 다음과 같은 명령으로 규칙을 설정할 수 있다.
$ iptables -A INPUT -p udp --dport=5001 -j LOG --log-level 1
해당 규칙에 의해 5001 포트를 목적지로 하는 수신 UDP 패킷을 syslog에 덤프할 것이다.
5001 포트를 목적지로 하는 UDP 패킷은 네트워크 드라이버에 도착하여 L3 계층으로 올라갈 때 NF_INET_PRE_ROUTING 훅을 만날 것이다.
하지만 필터 테이블 콜백은 해당 지점에 훅을 등록하지 않는다.
따라서, 그대로 ip_rcv_finish() 함수로 진행하여 라우팅 서브시스템 탐색을 수행한다.
이 후 로컬에 전달되거나 포워딩되는데, NF_INET_LOCAL_IN 훅이나 NF_INET_FORWARD 훅에서 등록된 iptable_filter_hook() 함수가 실행될 것이다.
iptable_filter_hook() 함수에서 ipt_do_table() 함수를 호출하여 등록된 규칙에 맞는 처리를 수행할 것이다.
로컬 호스트 전달
패킷이 로컬 호스트에 전달되는 경우 ip_local_deliver() 함수가 실행될 것이다.
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
위 정의처럼 NF_INET_LOCAL_IN 필터 테이블 훅이 있으므로, iptable_filter_hook() 함수를 호출할 것이다.
포워딩
패킷이 포워딩 되는 경우 ip_forward() 함수가 실행될 것이다.
int ip_forward(struct sk_buff *skb)
{
...
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
net, NULL, skb, skb->dev, rt->dst.dev,
ip_forward_finish);
sr_failed:
/*
* Strict routing permits no gatewaying
*/
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
too_many_hops:
/* Tell the sender its packet died... */
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
마찬가지로 NF_INET_FORWARD 필터 테이블 훅이 있으므로, iptable_filter_hook() 함수를 호출할 것이다.
NAT
NAT는 주로 IP 주소 변환이나 포트 조작을 다룬다.
넷필터 서브시스템 NAT 구현체에서는 -j 플래그를 사용하여 SNAT 또는 DNAT를 선택할 수 있다.
NAT 초기화
NAT 테이블은 필터 테이블과 마찬가지로 xt_table 구조체로 표현한다.
NAT 훅은 NF_INET_FORWARD 훅 지점을 제외한 모든 훅 지점에 등록된다.
static const struct xt_table nf_nat_ipv4_table = {
.name = "nat",
.valid_hooks = (1 << NF_INET_PRE_ROUTING) |
(1 << NF_INET_POST_ROUTING) |
(1 << NF_INET_LOCAL_OUT) |
(1 << NF_INET_LOCAL_IN),
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.table_init = iptable_nat_table_init,
};
각 훅 지점에 등록할 NAT 오퍼레이션 객체는 다음과 같다.
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
NAT 테이블 초기화는 iptable_nat_init() 함수에서 수행한다.
초기화 과정에서 호출하는 ipt_nat_register_lookups() 함수의 정의는 다음과 같다.
static int ipt_nat_register_lookups(struct net *net)
{
struct iptable_nat_pernet *xt_nat_net;
struct nf_hook_ops *ops;
struct xt_table *table;
int i, ret;
xt_nat_net = net_generic(net, iptable_nat_net_id);
table = xt_find_table(net, NFPROTO_IPV4, "nat");
if (WARN_ON_ONCE(!table))
return -ENOENT;
ops = kmemdup(nf_nat_ipv4_ops, sizeof(nf_nat_ipv4_ops), GFP_KERNEL);
if (!ops)
return -ENOMEM;
for (i = 0; i < ARRAY_SIZE(nf_nat_ipv4_ops); i++) {
ops[i].priv = table;
ret = nf_nat_ipv4_register_fn(net, &ops[i]);
if (ret) {
while (i)
nf_nat_ipv4_unregister_fn(net, &ops[--i]);
kfree(ops);
return ret;
}
}
xt_nat_net->nf_nat_ops = ops;
return 0;
}
int nf_nat_ipv4_register_fn(struct net *net, const struct nf_hook_ops *ops)
{
return nf_nat_register_fn(net, ops->pf, ops, nf_nat_ipv4_ops,
ARRAY_SIZE(nf_nat_ipv4_ops));
}
보이는 것과 같이 nf_nat_ipv4_register_fn() 함수가 호출되는데, 해당 함수에서 다음과 같이 NAT 오퍼레이션 객체를 등록한다.
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_pre_routing,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_out,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_local_fn,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_local_in,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
NAT 훅 콜백
오퍼레이션 객체에서 등록된 함수들(nf_nat_ipv4_local_fn(), nf_nat_ipv4_local_in() 등)의 정의를 보면 결국 nf_nat_ipv4_fn() 함수를 호출한다.
해당 함수의 정의는 다음과 같다.
static unsigned int
nf_nat_ipv4_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
ct = nf_ct_get(skb, &ctinfo);
if (!ct)
return NF_ACCEPT;
if (ctinfo == IP_CT_RELATED || ctinfo == IP_CT_RELATED_REPLY) {
if (ip_hdr(skb)->protocol == IPPROTO_ICMP) {
if (!nf_nat_icmp_reply_translation(skb, ct, ctinfo,
state->hook))
return NF_DROP;
else
return NF_ACCEPT;
}
}
return nf_nat_inet_fn(priv, skb, state);
}
연결 추적 정보를 구한 후, nf_nat_inet_fn() 함수를 호출한다.
해당 함수의 정의는 다음과 같다.
unsigned int
nf_nat_inet_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
struct nf_conn_nat *nat;
/* maniptype == SRC for postrouting. */
enum nf_nat_manip_type maniptype = HOOK2MANIP(state->hook);
ct = nf_ct_get(skb, &ctinfo);
/* Can't track? It's not due to stress, or conntrack would
* have dropped it. Hence it's the user's responsibilty to
* packet filter it out, or implement conntrack/NAT for that
* protocol. 8) --RR
*/
if (!ct)
return NF_ACCEPT;
nat = nfct_nat(ct);
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
/* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */
case IP_CT_NEW:
/* Seen it before? This can happen for loopback, retrans,
* or local packets.
*/
if (!nf_nat_initialized(ct, maniptype)) {
struct nf_nat_lookup_hook_priv *lpriv = priv;
struct nf_hook_entries *e = rcu_dereference(lpriv->entries);
unsigned int ret;
int i;
if (!e)
goto null_bind;
for (i = 0; i < e->num_hook_entries; i++) {
ret = e->hooks[i].hook(e->hooks[i].priv, skb,
state);
if (ret != NF_ACCEPT)
return ret;
if (nf_nat_initialized(ct, maniptype))
goto do_nat;
}
null_bind:
ret = nf_nat_alloc_null_binding(ct, state->hook);
if (ret != NF_ACCEPT)
return ret;
} else {
pr_debug("Already setup manip %s for ct %p (status bits 0x%lx)\n",
maniptype == NF_NAT_MANIP_SRC ? "SRC" : "DST",
ct, ct->status);
if (nf_nat_oif_changed(state->hook, ctinfo, nat,
state->out))
goto oif_changed;
}
break;
default:
/* ESTABLISHED */
WARN_ON(ctinfo != IP_CT_ESTABLISHED &&
ctinfo != IP_CT_ESTABLISHED_REPLY);
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
do_nat:
return nf_nat_packet(ct, ctinfo, state->hook, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
중복 훅 콜백
하나의 훅 지점에 여러 콜백이 등록될 수 있다.
NAT 콜백과 연결 추적 콜백이 모두 등록되는 훅 지점이 있다.
예를 들어 NF_INET_PRE_ROUTING 훅에 ipv4_conntrack_in()와 nf_nat_ipv4_pre_routing() 함수가 등록된다.
두 함수 각각 우선순위가 NF_IP_PRI_CONNTRACK(-200)와 NF_IP_PRI_NAT_DST(-100)이다.
우선순위가 낮은 ipv4_conntrack_in() 콜백이 먼저 호출되어, 연결 추적 계층에서 탐색을 먼저 수행한다.
해당 함수에서 연결 추적 항목을 찾지 못하면 nf_nat_ipv4_pre_routing() 함수에서 NAT 작업을 정상적으로 수행할 수 없게 된다.
예시로, 다음과 같은 DNAT 규칙을 만들 수 있다.
$ iptables -t nat -A PREROUTING -j DNAT -p udp --dport 9999 --to-destination 192.168.1.8
해당 규칙의 의미는 9999번 UDP 목적지 포트로 송신하는 UDP 패킷이 수신되면, 패킷의 목적지 IP 주소를 192.168.1.8로 변경하는 것이다.
이를 그림으로 나타내면 다음과 같다.
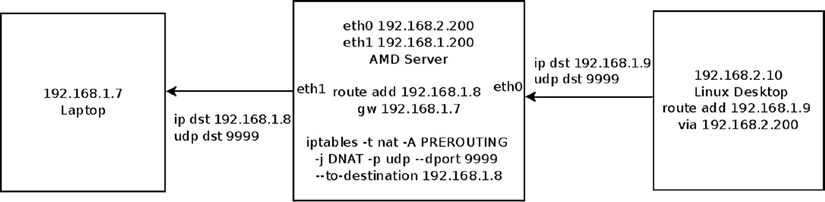 리눅스 데스크톱에서는 UDP 목적지 포트를 9999로 설정하여 192.168.1.9 주소로 UDP 패킷을 송신한다.
리눅스 데스크톱에서는 UDP 목적지 포트를 9999로 설정하여 192.168.1.9 주소로 UDP 패킷을 송신한다.
AMD 서버에서는 DNAT 규칙에 따라 목적지 주소를 192.168.1.8로 변경하여 패킷을 노트북에 송신한다.
다음 그림은 해당 상황에서의 UDP 패킷의 flow이다.
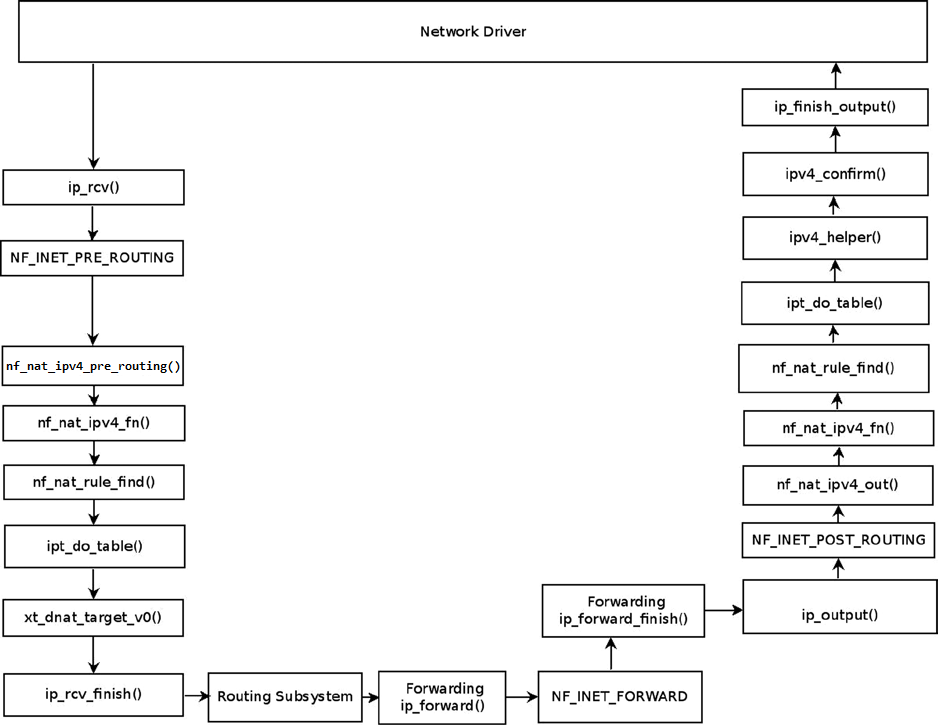
패킷 헤더를 변경하는 동작은 다음 nf_nat_hook 객체의 manip_pkt 멤버에 등록한 nf_nat_manip_pkt() 함수로 수행한다.
static struct nf_nat_hook nat_hook = {
.parse_nat_setup = nfnetlink_parse_nat_setup,
#ifdef CONFIG_XFRM
.decode_session = __nf_nat_decode_session,
#endif
.manip_pkt = nf_nat_manip_pkt,
};
unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,
enum nf_nat_manip_type mtype,
enum ip_conntrack_dir dir)
{
struct nf_conntrack_tuple target;
/* We are aiming to look like inverse of other direction. */
nf_ct_invert_tuple(&target, &ct->tuplehash[!dir].tuple);
switch (target.src.l3num) {
case NFPROTO_IPV6:
if (nf_nat_ipv6_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
case NFPROTO_IPV4:
if (nf_nat_ipv4_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
default:
WARN_ON_ONCE(1);
break;
}
return NF_DROP;
}
예제
http 메시지를 필터링하는 넷필터 모듈을 작성한다.
http_netfilter.c
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/netdevice.h>
static unsigned int hook_http(void *priv,
struct sk_buff *skb, const struct nf_hook_state *state)
{
struct iphdr *iph;
struct tcphdr *th;
char *data = NULL;
int length = 0;
if (!skb)
return NF_ACCEPT;
iph = ip_hdr(skb);
if (iph->protocol == IPPROTO_TCP) {
th = tcp_hdr(skb);
length = skb->len - iph->ihl * 4 - th->doff * 4;
if (length <= 4)
return NF_ACCEPT;
data = kzalloc(length, GFP_KERNEL);
memcpy(data, (unsigned char *)th + th->doff * 4, length);
if (strstr(data, "HTTP") != NULL) {
printk("[Kernel:%s] HTTP Detected\n", __func__);
kfree(data);
return NF_DROP;
}
kfree(data);
}
return NF_ACCEPT;
}
static struct nf_hook_ops *nf_ops = NULL;
static int __init nfilter_init(void)
{
nf_ops = (struct nf_hook_ops *)kzalloc(sizeof(struct nf_hook_ops), GFP_KERNEL);
nf_ops->hook = (nf_hookfn *)hook_http;
nf_ops->pf = PF_INET;
nf_ops->hooknum = NF_INET_LOCAL_IN;
nf_ops->priority = NF_IP_PRI_FIRST;
nf_register_net_hook(&init_net, nf_ops);
printk("[Kernel:%s] NFilter Init\n", __func__);
return 0;
}
static void __exit nfilter_exit(void)
{
nf_unregister_net_hook(&init_net, nf_ops);
kfree(nf_ops);
printk("[Kernel:%s] NFilter Exit\n", __func__);
}
module_init(nfilter_init);
module_exit(nfilter_exit);
MODULE_LICENSE("GPL");
Makefile
obj-m += http_netfilter.o
KDIR := /lib/modules/$(shell uname -r)/build
default:
$(MAKE) -C $(KDIR) M=$(PWD) modules
CC := gcc
%.c%:
${CC} -o $@ $^
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean
rm -f ${TARGETS}
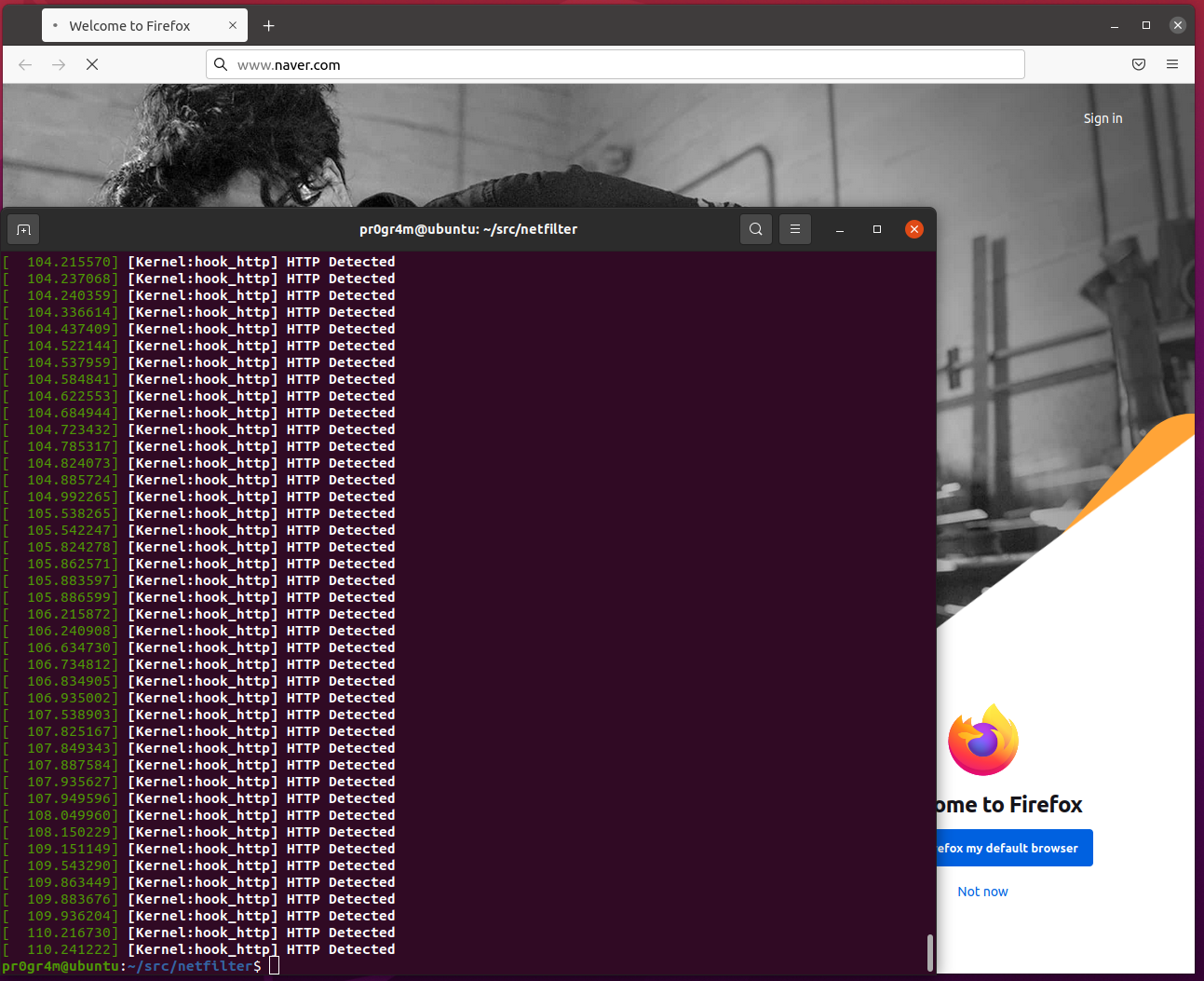
빌드 및 결과
위의 소스 코드들은 커널 디렉토리가 아닌 일반 디렉토리에서 작성하여 다음과 같이 빌드 및 실행한다.
$ make
$ sudo insmod http_netfilter.ko
이 후 웹 브라우저로 웹 서핑 시 패킷 중 HTTP 라는 문자열이 포함 된 패킷은 drop 되어 브라우징이 되지 않을 것이다.
dmesg로 커널 메시지를 확인하면 다음과 같다.