Linux Kernel ICMPv4
해당 포스트에서는 리눅스 커널의 ICMPv4 구현에 대해 설명합니다.
ICMPv4
ICMPv4 메시지는 오류 메시지와 정보 메시지로 나눌 수 있다.
ICMPv4 프로토콜을 사용하는 대표적인 유틸리티는 다음과 같다.
- ping : raw 소켓을 통해 ICMP_ECHO 메시지를 보내고, ICMP_REPLY 메시지를 회신
- traceroute : TTL 값이 0이 되면 포워딩 장비가 ICMP_TIME_EXCEED 메시지를 회신
- TTL 값이 1인 메시지를 전송하는 것으로 시작하여 응답으로 ICMP_TIME_EXCEED 코드가 지정된 ICMP_DEST_UNREACH를 받을 때마다 TTL을 1 증가시켜 같은 목적지로 재전송
- 반환된 Time Exceeded ICMP 메시지를 이용해 패킷이 이동한 라우터 목록을 만듦
- UDP 프로토콜을 사용
ICMPv4 헤더
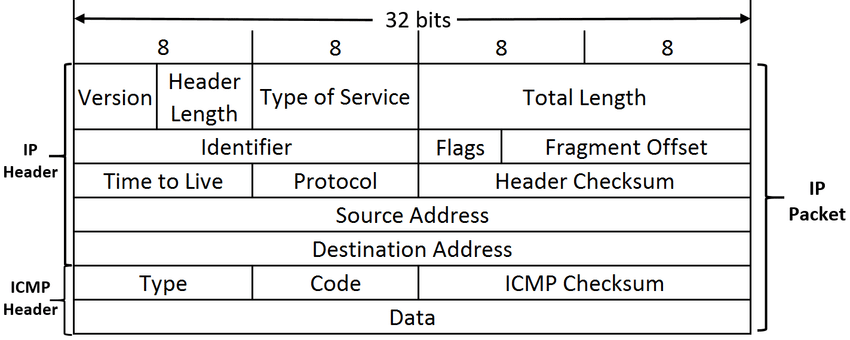
- Type(8비트), Code(8비트), Checksum(16비트), Optional Data(32비트), Payload
- ICMPv4 오류 메시지의 데이터그램 길이는 576 바이트를 초과하지 않아야 함 (RFC791 -> RFC1812)
struct icmphdr {
__u8 type;
__u8 code;
__sum16 checksum;
union {
struct {
__be16 id;
__be16 sequence;
} echo;
__be32 gateway;
struct {
__be16 __unused;
__be16 mtu;
} frag;
__u8 reserved[4];
} un;
};
ICMPv4 초기화
ICMPv4 초기화는 부팅 시 inet_init() 함수에서 다음과 같이 수행한다.
static int __init inet_init(void)
{
...
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
...
ping_init();
/*
* Set the ICMP layer up
*/
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
...
}
inet_add_protocol() 함수는 커널에 특정 프로토콜에 대한 핸들러를 등록한다.
(net_protocol 타입의 전역 변수 배열 inet_protos에 인자로 전달받은 net_protocol 타입 객체를 등록한다.)
icmp_protocol 변수는 net_protocol 구조체의 인스턴스로 다음과 같다.
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
- icmp_rcv : IP 헤더의 프로토콜 필드가 IPPROTO_ICMP인 수신 패킷에 대해 icmp_rcv() 함수가 호출된다.
- no_policy : 해당 플래그가 1로 설정되면 IPsec policy 검사를 수행할 필요가 없음을 의미한다.
- netns_ok : 해당 플래그가 1로 설정되면, 이는 프로토콜이 네트워크 네임스페이스를 알고 있음을 나타낸다.
또한, icmp_init() 함수에서는 register_pernet_subsys() 함수로 init/exit operation을 등록하는데, 결국 초기화를 위하여 icmp_sk_init() 함수를 호출하도록 되어 있다.
static int __net_init icmp_sk_init(struct net *net)
{
int i, err;
net->ipv4.icmp_sk = alloc_percpu(struct sock *);
if (!net->ipv4.icmp_sk)
return -ENOMEM;
for_each_possible_cpu(i) {
struct sock *sk;
// RAW ICMP 소켓 생성
err = inet_ctl_sock_create(&sk, PF_INET,
SOCK_RAW, IPPROTO_ICMP, net);
if (err < 0)
goto fail;
// 각 CPU 마다 생성된 소켓 보관
*per_cpu_ptr(net->ipv4.icmp_sk, i) = sk;
/* Enough space for 2 64K ICMP packets, including
* sk_buff/skb_shared_info struct overhead.
*/
sk->sk_sndbuf = 2 * SKB_TRUESIZE(64 * 1024);
/*
* Speedup sock_wfree()
*/
sock_set_flag(sk, SOCK_USE_WRITE_QUEUE);
inet_sk(sk)->pmtudisc = IP_PMTUDISC_DONT;
}
/* Control parameters for ECHO replies. */
net->ipv4.sysctl_icmp_echo_ignore_all = 0;
net->ipv4.sysctl_icmp_echo_enable_probe = 0;
net->ipv4.sysctl_icmp_echo_ignore_broadcasts = 1;
/* Control parameter - ignore bogus broadcast responses? */
net->ipv4.sysctl_icmp_ignore_bogus_error_responses = 1;
/*
* Configurable global rate limit.
*
* ratelimit defines tokens/packet consumed for dst->rate_token
* bucket ratemask defines which icmp types are ratelimited by
* setting it's bit position.
*
* default:
* dest unreachable (3), source quench (4),
* time exceeded (11), parameter problem (12)
*/
net->ipv4.sysctl_icmp_ratelimit = 1 * HZ;
net->ipv4.sysctl_icmp_ratemask = 0x1818;
net->ipv4.sysctl_icmp_errors_use_inbound_ifaddr = 0;
return 0;
fail:
icmp_sk_exit(net);
return err;
}
위 코드의 주석부분에서 설명한 각 CPU마다 생성한 RAW ICMP 소켓은 icmp_push_reply() 함수에서 사용된다.
icmp_push_reply() 함수는 이 후 메시지 송신 파트에서 설명한다.
ICMPv4 메시지 수신
ICMPv4 메시지는 다음 링크와 같이 여러 형식이 존재한다.
각 메시지 타입들은 icmp_control 객체의 배열 icmp_pointers에 대해 다음과 같이 핸들러를 등록한다.
/*
* ICMP control array. This specifies what to do with each ICMP.
*/
struct icmp_control {
bool (*handler)(struct sk_buff *skb);
short error; /* This ICMP is classed as an error message */
};
/*
* This table is the definition of how we handle ICMP.
*/
static const struct icmp_control icmp_pointers[NR_ICMP_TYPES + 1] = {
[ICMP_ECHOREPLY] = {
.handler = ping_rcv,
},
[1] = {
.handler = icmp_discard,
.error = 1,
},
[2] = {
.handler = icmp_discard,
.error = 1,
},
[ICMP_DEST_UNREACH] = {
.handler = icmp_unreach,
.error = 1,
},
[ICMP_SOURCE_QUENCH] = {
.handler = icmp_unreach,
.error = 1,
},
[ICMP_REDIRECT] = {
.handler = icmp_redirect,
.error = 1,
},
[6] = {
.handler = icmp_discard,
.error = 1,
},
[7] = {
.handler = icmp_discard,
.error = 1,
},
[ICMP_ECHO] = {
.handler = icmp_echo,
},
[9] = {
.handler = icmp_discard,
.error = 1,
},
[10] = {
.handler = icmp_discard,
.error = 1,
},
[ICMP_TIME_EXCEEDED] = {
.handler = icmp_unreach,
.error = 1,
},
[ICMP_PARAMETERPROB] = {
.handler = icmp_unreach,
.error = 1,
},
[ICMP_TIMESTAMP] = {
.handler = icmp_timestamp,
},
[ICMP_TIMESTAMPREPLY] = {
.handler = icmp_discard,
},
[ICMP_INFO_REQUEST] = {
.handler = icmp_discard,
},
[ICMP_INFO_REPLY] = {
.handler = icmp_discard,
},
[ICMP_ADDRESS] = {
.handler = icmp_discard,
},
[ICMP_ADDRESSREPLY] = {
.handler = icmp_discard,
},
};
이렇게 등록된 핸들러는 icmp_rcv() 함수에서 다음과 같이 타입에 따라 호출된다.
int icmp_rcv(struct sk_buff *skb)
{
...
icmph = icmp_hdr(skb);
...
success = icmp_pointers[icmph->type].handler(skb);
...
}
즉, ICMP_ECHOREPLY 메시지를 수신하면 ping_rcv() 함수로 처리하고, ICMP_ECHO 메시지를 수신하면 icmp_echo() 함수로 처리하는 방식이다.
icmp_discard() 함수는 legacy 메시지를 처리하는 빈 함수이다.
icmp_redirect() 함수는 ICMP_REDIRECT 메시지를 처리하는 함수이다.
icmp_unreach() 함수는 ICMP_DEST_UNREACH, IMCP_TIME_EXCEEDED 등의 메시지를 처리하는데 사용된다.
ICMP_DEST_UNREACH 메시지는 다양한 조건에서 전송될 수 있다.
ICMP_TIME_EXCEEDED 메시지는 다음과 같은 경우에 전송된다.
- ip_forward() 함수에서 TTL이 0이 되면 다음과 같이 호출한다.
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0); - ip_expire() 함수에서 단편화된 패킷에서 타임아웃이 발생하면 다음과 같이 호출한다.
icmp_send(head, ICMP_TIME_EXCEEDED, ICMP_EXC_FRAGTIME, 0);
ICMPv4 메시지 송신
ICMP 메시지 송신은 다음 두 가지 함수에서 진행된다.
static void icmp_reply(struct icmp_bxm *icmp_param, struct sk_buff *skb): ICMP 요청인 ICMP_ECHO와 ICMP_TIMESTAMP에 대한 응답으로서 전송한다.void __icmp_send(struct sk_buff *skb_in, int type, int code, __be32 info, const struct ip_options *opt): 로컬 장비가 특정한 조건에서 ICMPv4 메시지를 전송한다.
ftrace를 이용하여 ping 메시지를 수신하고 응답하는 과정을 트레이싱 하면 다음과 같다.
# tracer: function
#
# entries-in-buffer/entries-written: 4/4 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [003] ..s. 14084.047681: icmp_reply.constprop.0 <-icmp_echo.part.0
<idle>-0 [003] ..s. 14084.047683: <stack trace>
=> icmp_reply.constprop.0
=> icmp_echo.part.0
=> icmp_echo
=> icmp_rcv
=> ip_protocol_deliver_rcu
=> ip_local_deliver_finish
=> ip_local_deliver
=> ip_sublist_rcv_finish
=> ip_sublist_rcv
=> ip_list_rcv
=> __netif_receive_skb_list_core
=> netif_receive_skb_list_internal
=> gro_normal_list.part.0
=> napi_complete_done
=> e1000_clean
=> net_rx_action
=> __do_softirq
=> asm_call_irq_on_stack
=> do_softirq_own_stack
=> irq_exit_rcu
=> common_interrupt
=> asm_common_interrupt
=> native_safe_halt
=> acpi_idle_enter
=> cpuidle_enter_state
=> cpuidle_enter
=> call_cpuidle
=> do_idle
=> cpu_startup_entry
=> start_secondary
=> secondary_startup_64
=> 0xb50000e1ffffffff
=> 0xb4e01102ffffffff
=> 0xb423679dffffffff
=> 0xb42a8764ffffffff
=> 0xb4d7793dffffffff
=> 0xb4e00c1effffffff
=> 0x328c0ffffffff
=> 0x10000400000124
함수 호출 스택을 보면 icmp_rcv() 함수에서 ICMP_ECHO 메시지를 처리하기 위하여 icmp_echo() 핸들러를 호출하고, 해당 핸들러에서 icmp_reply() 함수를 호출하는 것을 볼 수 있다.
이 외에도 아래 ip 스택 함수들도 볼 수 있는데, 해당 내용은 추후 IPv4 챕터에서 설명하기로 한다.
icmp_send() 함수는 사실 __icmp_send() 함수의 래퍼이다.
__icmp_send() 함수에서는 패킷의 header를 변경시키면 안 되고, 멀티캐스트/브로드캐스트 주소에 reply 하면 안 되며, 단편화 패킷의 경우 첫 fragment 패킷에만 reply 해야 한다.
또한, ICMP 오류 메시지는 ICMP 오류 메시지를 수신한 결과로서 전송되면 안 된다.
이러한 온전성/제한 검사들을 통과하면, icmp_route_lookup() 함수로 라우터 테이블 lookup을 진행한 후, icmp_push_reply()함수로 실제 패킷을 전송한다.
icmp_send() 함수의 원형은 다음과 같다.
static inline void icmp_send(struct sk_buff *skb_in, int type, int code, __be32 info)
- skb_in : 해당 함수가 호출되게 한 SKB
- type : ICMPv4 메시지의 type
- code : ICMPv4 메시지의 code
- info : 추가적인 정보를 담고 있는 매개 변수로 다음과 같은 경우 사용된다.
- ICMP_PARAMETERPROB 메시지 형식의 경우 info는 구문 해석 문제가 발생한 IPv4 헤더의 오프셋이다.
- ICMP_FRAG_NEEDED 코드가 지정된 ICMP_DEST_UNREACH 메시지 형식의 경우 MTU이다.
- ICMP_REDIR_HOST 코드가 지정된 ICMP_REDIRECT 메시지 형식의 경우 수신한 SKB의 목적지 IP 주소이다. 아래에는 icmp_send() 함수가 호출되는 경우들을 설명한다.
ICMP_DEST_UNREACH
ICMP_DEST_UNREACH 메시지에는 아래와 같은 세부 코드들이 있다.
ICMP_PROT_UNREACH
IP 헤더의 프로토콜이 존재하지 않는 프로토콜이면 ICMP_DEST_UNREACH/ICMP_PROT_UNREACH 메시지가 회신된다.
존재하지 않는 프로토콜이 생기는 경우는 실제 오류이거나, 커널이 해당 프로토콜을 지원하지 않는 상태로 빌드된 경우이다.
해당 경우엔 패킷을 처리할 핸들러가 없기 때문에 “목적지에 연결할 수 없음”이라는 ICMP 메시지가 회신된다.
아래는 해당 부분을 처리하는 코드이다.
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
if (!ipprot->no_policy) {
...
} else {
if (!raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH,
ICMP_PROT_UNREACH, 0);
}
kfree_skb(skb);
} else {
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
}
ICMP_PORT_UNREACH
UDPv4 패킷을 수신하면 그에 일치하는 UDP 소켓을 찾는다. 일치하는 소켓이 없는 경우 체크섬을 확인한다.
체크섬이 잘못된 경우에는 단순히 패킷을 drop하지만, 체크섬이 정확한 경우엔 통계를 업데이트하고 ICMP_DEST_UNREACH/ICMP_PORT_UNREACH 메시지를 회신한다.
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto)
{
struct sock *sk;
...
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk)
return udp_unicast_rcv_skb(sk, skb, uh);
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto drop;
nf_reset_ct(skb);
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb))
goto csum_error;
__UDP_INC_STATS(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
...
}
__udp4_lib_lookup_skb() 함수로 udp table lookup을 수행하고, 소켓이 없는 경우 csum_error 처리 루틴으로 가거나 “포트에 연결할 수 없음” 메시지를 회신한다.
ICMP_FRAG_NEEDED
MTU보다 길이가 긴 패킷을 포워딩할 경우 ICMP_DEST_UNREACH/ICMP_FRAG_NEEDED 메시지를 송신자에게 회신하고 패킷을 drop한다.
int ip_forward(struct sk_buff *skb)
{
u32 mtu;
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
struct net *net;
...
mtu = ip_dst_mtu_maybe_forward(&rt->dst, true);
if (ip_exceeds_mtu(skb, mtu)) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
goto drop;
}
...
}
static bool ip_exceeds_mtu(const struct sk_buff *skb, unsigned int mtu)
{
if (skb->len <= mtu)
return false;
if (unlikely((ip_hdr(skb)->frag_off & htons(IP_DF)) == 0))
return false;
/* original fragment exceeds mtu and DF is set */
if (unlikely(IPCB(skb)->frag_max_size > mtu))
return true;
if (skb->ignore_df)
return false;
if (skb_is_gso(skb) && skb_gso_validate_network_len(skb, mtu))
return false;
return true;
}
ICMP_SR_FAILED
패킷에 strict route 옵션이 설정되어 있는 경우엔 게이트웨이 사용이 제한된다. 따라서, strict route 옵션이 설정되어 있고 게이트웨이로 포워딩하는 경우 ICMP_DEST_UNREACH/ICMP_SR_FAILED 메시지를 회신하고 패킷은 drop된다.
int ip_forward(struct sk_buff *skb)
{
u32 mtu;
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
struct net *net;
...
if (opt->is_strictroute && rt->rt_uses_gateway)
goto sr_failed;
sr_failed:
/*
* Strict routing permits no gatewaying
*/
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
...
}
속도 제한
icmp_reply()와 icmp_send() 함수 모두 속도 제한을 지원한다. 두 함수는 icmpv4_xrlim_allow() 함수를 호출하고, 속도 제한 검사에서 패킷 전송을 허용하면 패킷을 전송한다. icmpv4_xrlim_allow() 함수는 다음과 같으며, true를 반환하면 패킷을 허용한다.
/*
* Send an ICMP frame.
*/
static bool icmpv4_xrlim_allow(struct net *net, struct rtable *rt,
struct flowi4 *fl4, int type, int code)
{
struct dst_entry *dst = &rt->dst;
struct inet_peer *peer;
bool rc = true;
int vif;
if (icmpv4_mask_allow(net, type, code))
goto out;
/* No rate limit on loopback */
if (dst->dev && (dst->dev->flags&IFF_LOOPBACK))
goto out;
vif = l3mdev_master_ifindex(dst->dev);
peer = inet_getpeer_v4(net->ipv4.peers, fl4->daddr, vif, 1);
rc = inet_peer_xrlim_allow(peer, net->ipv4.sysctl_icmp_ratelimit);
if (peer)
inet_putpeer(peer);
out:
return rc;
}
다음과 같은 경우 속도 제한 검사를 수행하지 않는다.
- 루프백 장치의 경우
- 장치의 icmp mask에 해당 type(ICMP_DEST_UNREACH)/code(ICMP_FRAG_NEEDED 등)이 설정되지 않은 경우
위의 경우가 아니라면 inet_peer_xrlim_allow() 함수를 통해 속도 제한이 수행된다.
icmp_push_reply
icmp_reply() 함수와 icmp_send() 함수 모두 결국 실제 패킷을 전송하기 위하여 icmp_push_reply()함수를 호출한다. 해당 함수의 정의는 다음과 같다.
static void icmp_push_reply(struct icmp_bxm *icmp_param,
struct flowi4 *fl4,
struct ipcm_cookie *ipc, struct rtable **rt)
{
struct sock *sk;
struct sk_buff *skb;
sk = icmp_sk(dev_net((*rt)->dst.dev)); // CPU에 할당된 RAW ICMP 소켓에 접근
if (ip_append_data(sk, fl4, icmp_glue_bits, icmp_param,
icmp_param->data_len+icmp_param->head_len,
icmp_param->head_len,
ipc, rt, MSG_DONTWAIT) < 0) {
__ICMP_INC_STATS(sock_net(sk), ICMP_MIB_OUTERRORS);
ip_flush_pending_frames(sk);
} else if ((skb = skb_peek(&sk->sk_write_queue)) != NULL) {
struct icmphdr *icmph = icmp_hdr(skb);
__wsum csum;
struct sk_buff *skb1;
csum = csum_partial_copy_nocheck((void *)&icmp_param->data,
(char *)icmph,
icmp_param->head_len);
skb_queue_walk(&sk->sk_write_queue, skb1) {
csum = csum_add(csum, skb1->csum);
}
icmph->checksum = csum_fold(csum);
skb->ip_summed = CHECKSUM_NONE;
ip_push_pending_frames(sk, fl4);
}
}
위 함수에서는 icmp_sk_init() 함수에서 생성한 소켓을 다음 코드로 접근한다.
sk = icmp_sk(dev_net((*rt)->dst.dev)); // CPU에 할당된 RAW ICMP 소켓에 접근
dev_net() 함수는 외부로 보낼 네트워크 장치의 네트워크 네임스페이스를 반환한다.
icmp_sk() 함수는 해당 네트워크 네임스페이스의 ICMPv4 소켓을 this_cpu_read() 함수로 가져온다.
그 후 ip_append_data() 함수를 호출하여 패킷을 IP 계층으로 옮긴다.
예제
linux/net/ipv4/ip_km.h
net/ipv4 디렉토리 아래에 작업용 헤더 파일을 하나 추가한다.
원래는 절대 소스 디렉토리에 헤더 파일을 추가하면 안 되고, 해당 파일은 include/net 디렉토리 아래에 위치해야 하지만, 편의를 위해 해당 디렉토리에 위치시켰다. (추후 변경될 수 있음)
#ifndef _IP_KM_H
#define _IP_KM_H
#include <linux/types.h>
#include <linux/kernel.h>
#include <linux/skbuff.h>
#define KM_DEBUG_IP_RCV 16
#define KM_DEBUG_ICMP_RCV 17
extern uint32_t km_debug_state;
static void print_skb(struct sk_buff *skb)
{
int i = 0, j = 0;
printk("%7s", "offset ");
for (i = 0; i < 16; i++) {
printk(KERN_CONT "%02x ", i);
if (!(i % 16 - 7))
printk(KERN_CONT "- ");
}
printk(KERN_CONT "\n");
for (i = 0; i < skb->len; i++) {
if (!(i % 16))
printk(KERN_CONT "0x%04x ", i);
printk(KERN_CONT "%02x ", skb->data[i]);
if (!(i % 16 - 7))
printk(KERN_CONT "- ");
if (!(i % 16 - 15)) {
printk(KERN_CONT "\t");
for (j = i - 15; j <= i; j++) {
printk(KERN_CONT "%c", skb->data[j] >= 0x20 && skb->data[j] < 0x80 ? skb->data[j] : '.');
}
printk(KERN_CONT "\n");
}
}
printk("\n");
}
#endif
이 전에 만들어둔 debug filesystem의 변수와 print_skb 함수를 선언한다.
linux/net/ipv4/af_inet.c
1757 라인에 다음 코드를 추가한다.
static const struct net_protocol icmp_protocol_km = {
.handler = icmp_rcv_km,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
inet_init 함수의 IPPROTO_ICMP 등록부분을 다음과 같이 변경한다 (1982 라인)
// 기존
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
// 변경 후
if (inet_add_protocol(&icmp_protocol_km, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
위 상황에서는 IP 헤더의 ICMP 프로토콜 핸들러가 icmp_rcv 함수에서 icmp_rcv_km 함수로 변경되었다.
include/net/icmp.h
헤더 파일의 57 라인에 다음 내용을 추가한다.
...
int icmp_rcv(struct sk_buff *skb);
int icmp_rcv_km(struct sk_buff *skb); // 추가된 라인
int icmp_err(struct sk_buff *skb, u32 info);
linux/net/ipv4/icmp.c
96 라인에 다음과 같이 헤더 파일을 추가한다.
#include "ip_km.h"
1121 라인에 다음과 같이 icmp_rcv_km 함수를 정의한다.
int icmp_rcv_km(struct sk_buff *skb)
{
struct icmphdr *icmph;
struct rtable *rt = skb_rtable(skb);
struct net *net = dev_net(rt->dst.dev);
bool success;
// 기존 icmp_rcv 함수에서 변경된 부분
if (km_debug_state == KM_DEBUG_ICMP_RCV)
print_skb(skb);
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
struct sec_path *sp = skb_sec_path(skb);
int nh;
if (!(sp && sp->xvec[sp->len - 1]->props.flags &
XFRM_STATE_ICMP))
goto drop;
if (!pskb_may_pull(skb, sizeof(*icmph) + sizeof(struct iphdr)))
goto drop;
nh = skb_network_offset(skb);
skb_set_network_header(skb, sizeof(*icmph));
if (!xfrm4_policy_check_reverse(NULL, XFRM_POLICY_IN, skb))
goto drop;
skb_set_network_header(skb, nh);
}
__ICMP_INC_STATS(net, ICMP_MIB_INMSGS);
if (skb_checksum_simple_validate(skb))
goto csum_error;
if (!pskb_pull(skb, sizeof(*icmph)))
goto error;
icmph = icmp_hdr(skb);
ICMPMSGIN_INC_STATS(net, icmph->type);
/*
* 18 is the highest 'known' ICMP type. Anything else is a mystery
*
* RFC 1122: 3.2.2 Unknown ICMP messages types MUST be silently
* discarded.
*/
if (icmph->type > NR_ICMP_TYPES)
goto error;
/*
* Parse the ICMP message
*/
if (rt->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST)) {
/*
* RFC 1122: 3.2.2.6 An ICMP_ECHO to broadcast MAY be
* silently ignored (we let user decide with a sysctl).
* RFC 1122: 3.2.2.8 An ICMP_TIMESTAMP MAY be silently
* discarded if to broadcast/multicast.
*/
if ((icmph->type == ICMP_ECHO ||
icmph->type == ICMP_TIMESTAMP) &&
net->ipv4.sysctl_icmp_echo_ignore_broadcasts) {
goto error;
}
if (icmph->type != ICMP_ECHO &&
icmph->type != ICMP_TIMESTAMP &&
icmph->type != ICMP_ADDRESS &&
icmph->type != ICMP_ADDRESSREPLY) {
goto error;
}
}
success = icmp_pointers[icmph->type].handler(skb);
if (success) {
consume_skb(skb);
return NET_RX_SUCCESS;
}
drop:
kfree_skb(skb);
return NET_RX_DROP;
csum_error:
__ICMP_INC_STATS(net, ICMP_MIB_CSUMERRORS);
error:
__ICMP_INC_STATS(net, ICMP_MIB_INERRORS);
goto drop;
}
위 함수는 기존 icmp_rcv() 함수를 그대로 복사한 후, 코드 상단에 print_skb 함수를 이용하여 SKB의 data를 출력한다.
빌드 및 결과
linux root 디렉토리에서 다음과 같이 빌드한다.
$ make -j8
$ sudo make install
재부팅 후 다음과 같이 km_debug_state 값을 17로 수정한다.
# root 계정으로 작업해야 함
$ echo 17 > /sys/kernel/debug/km_debug/val
이 후 해당 머신에 ping을 보내면 dmesg에 SKB 데이터가 출력되는 것을 볼 수 있다.
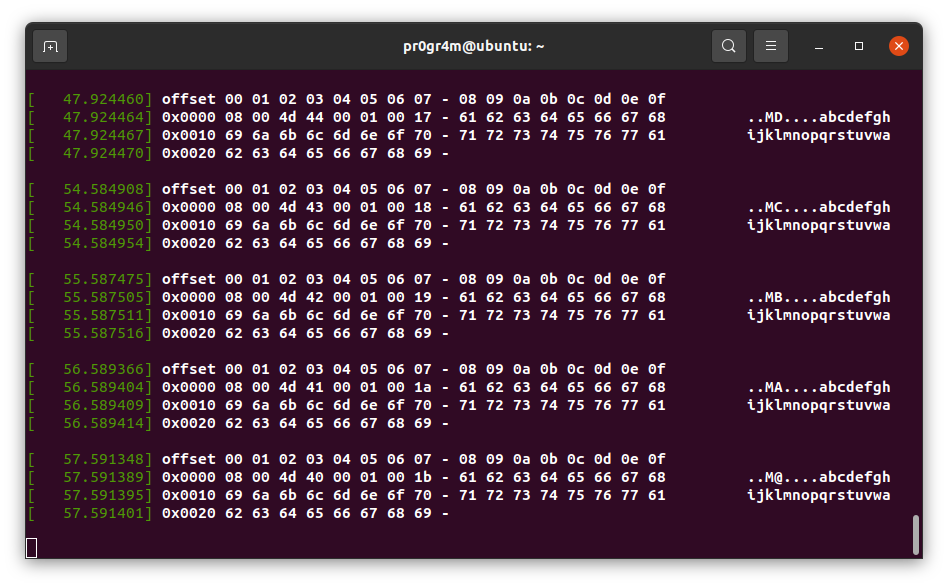
위 결과는 새로 정의한 함수(icmp_rcv_km)를 ICMP 프로토콜 핸들러로 등록한 결과이다.
이를 응용하면 새로운 프로토콜을 정의하거나, 기존 프로토콜에 대한 핸들러를 자유롭게 수정할 수 있다.