Linux Kernel IPv4
해당 포스트에서는 리눅스 커널의 IPv4 구현에 대해 설명합니다.
IPv4
IPv4는 Packet Switching Network 상에서 데이터를 교환하기 위한 프로토콜이다.
네트워크 계층에서 호스트의 주소 지정 및 라우팅과 패킷 분할 및 조립 기능을 담당한다.
IPv4 상에서는 reliability와 connection을 보장하지는 않는다.
IPv4 헤더
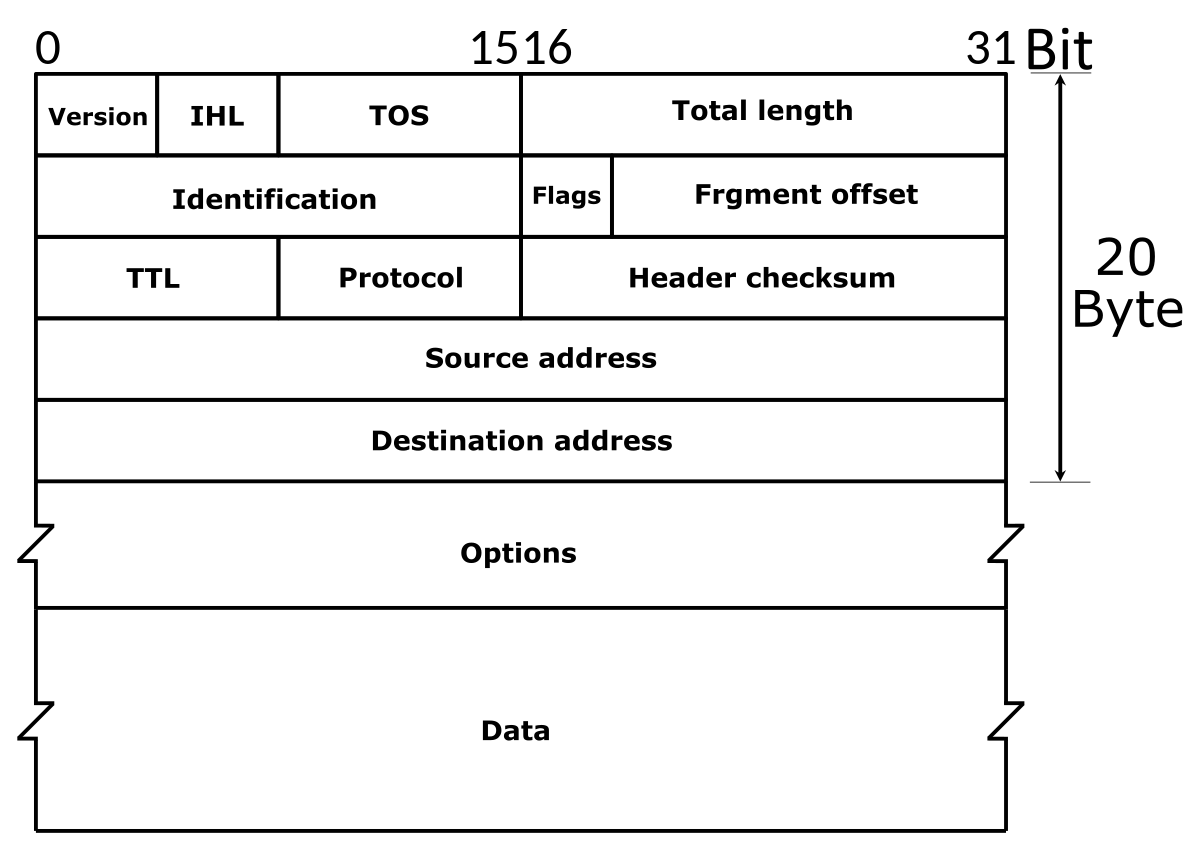
IPv4 헤더는 고정된 20바이트 필드와, 0바이트에서 40바이트의 옵션 필드로 구성된다.
커널에서 구현한 IPv4 헤더 구조체는 다음과 같다.
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
- ihl : Internet Header Length의 약어이다. IPv4 헤더의 길이는 4바이트 배수로 계산한다. IPv4 헤더의 크기가 20 ~ 60바이트 이기 때문에, 해당 필드는 5 ~ 15의 값을 갖는다.
- version : IPv4 헤더의 버전은 항상 4이다.
- tos : Type of Service의 약어로 원래 QoS를 나타낼 의도로 만들어진 필드이다. 실제로는 0 ~ 5 비트를 Differentiated Services 필드로 사용하고, 6 ~ 7 비트를 Explicit Congetion Notification 필드로 사용한다.
- tot_len : 헤더를 포함한 전체 길이로서 바이트 단위로 계산한다. 16비트이므로 최대 64KB까지 표현할 수 있다. RFC 791에 따라 최소 크기는 576 바이트이다.
- id : IPv4 헤더의 식별자이다. SKB를 단편화하면 단편화된 모든 SKB의 id 값이 같아야한다. 해당 필드를 이용하여 단편화된 패킷을 재조립한다.
- frag_off : 하위 13비트는 단편화의 오프셋이며 상위 3비트는 플래그이다. 첫 단편화 패킷에서는 오프셋이 0이며, 오프셋은 8바이트 단위로 계산한다. 플래그는 다음과 같다.
- 001 : More Fragments로 마지막 하나를 제외한 모든 단편화된 패킷에 설정된다.
- 010 : Don’t Fragment로 단편화할 수 없는 패킷에 설정된다.
- 100 : Congetion으로 혼잡 플래그이다.
- ttl : Time To Live 필드이다. 각 포워딩 노드마다 ttl 값이 1씩 줄어들고, 0이 되면 패킷은 폐기되며 시간 초과 ICMP 메시지가 회신된다.
- protocol : 패킷의 L4 프로토콜 필드이다. IPPROTO_TCP 등이 설정되며, 해당 링크 에서 리스트를 볼 수 있다.
- check : 체크섬 필드로, IPv4 헤더 바이트에 대해서만 계산된다.
- saddr : Source IPv4 주소
- daddr : Destination IPv4 주소
IPv4 초기화
IPv4 초기화는 다음과 같이 부팅 시에 inet_init() 함수에서 진행한다.
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc;
...
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
...
/*
* Set the IP module up
*/
ip_init();
...
/*
* Initialise the multicast router
*/
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);
#endif
...
if (init_inet_pernet_ops())
pr_crit("%s: Cannot init ipv4 inet pernet ops\n", __func__);
/*
* Initialise per-cpu ipv4 mibs
*/
if (init_ipv4_mibs())
pr_crit("%s: Cannot init ipv4 mibs\n", __func__);
ipv4_proc_init();
ipfrag_init();
dev_add_pack(&ip_packet_type);
ip_tunnel_core_init();
...
}
#ifdef CONFIG_PROC_FS
static int __init ipv4_proc_init(void)
{
int rc = 0;
if (raw_proc_init())
goto out_raw;
if (tcp4_proc_init())
goto out_tcp;
if (udp4_proc_init())
goto out_udp;
if (ping_proc_init())
goto out_ping;
if (ip_misc_proc_init())
goto out_misc;
out:
return rc;
out_misc:
ping_proc_exit();
out_ping:
udp4_proc_exit();
out_udp:
tcp4_proc_exit();
out_tcp:
raw_proc_exit();
out_raw:
rc = -ENOMEM;
goto out;
}
#else /* CONFIG_PROC_FS */
static int __init ipv4_proc_init(void)
{
return 0;
}
#endif /* CONFIG_PROC_FS */
void __init ip_init(void)
{
ip_rt_init();
inet_initpeers();
#if defined(CONFIG_IP_MULTICAST)
igmp_mc_init();
#endif
}
dev_add_pack() 함수에서 ip_rcv() 함수를 IPv4 패킷에 대한 프로토콜 핸들러로 추가한다.
packet_type 구조체에서는 패킷의 핸들러를 등록할 수 있다.
list_func 멤버는 multiple received packets를 처리하기 위한 listified receive 함수를 등록할 수 있다.
IPv4 패킷은 L2 레이어에서 이더넷 타입이 0x0800인 패킷으로 식별한다.
ip_init() 함수에서는 라우팅 테이블이나 IGMP 관련 초기화를 수행한다.
IPv4 패킷 수신
IPv4 패킷 수신 Flow를 간단하게 도식화하면 다음과 같다.
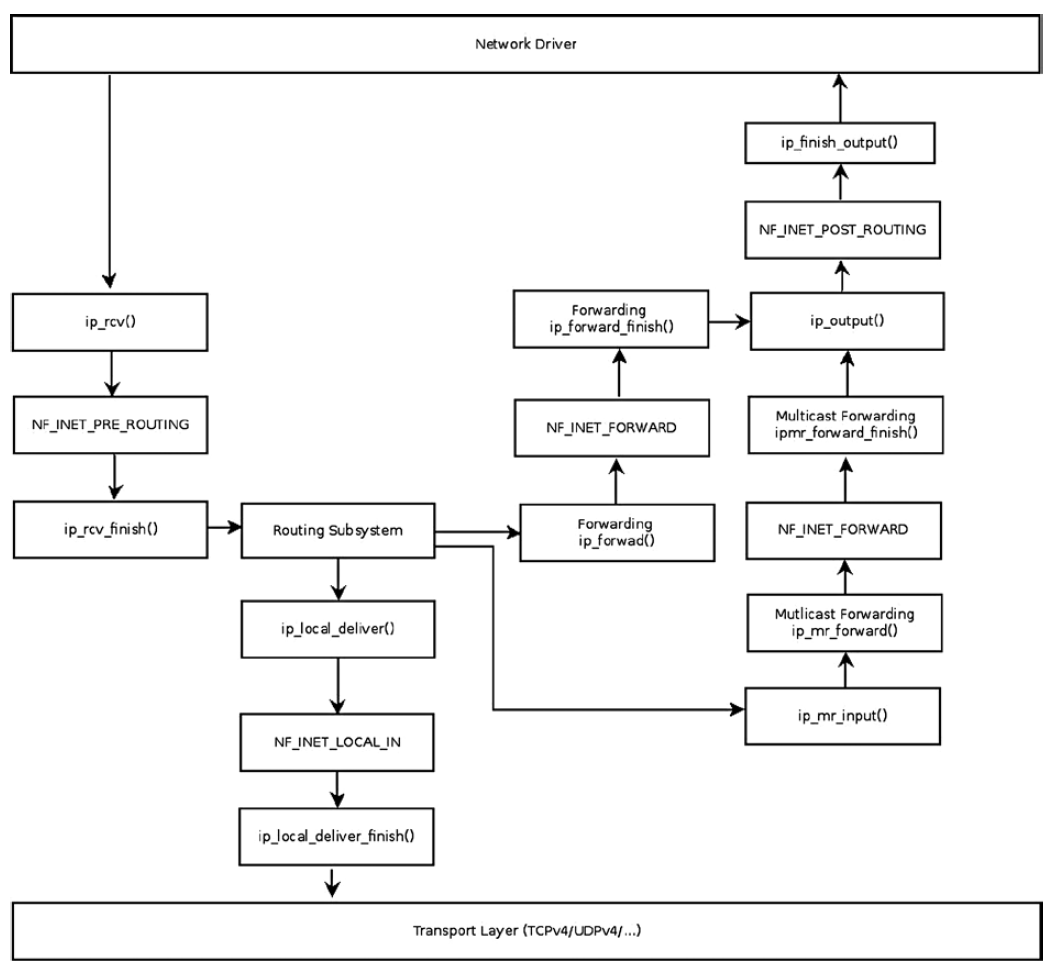 다이어그램 중간에 위치하는 넷필터 관련 훅들은 이 후 넷필터 챕터에서 설명한다.
다이어그램 중간에 위치하는 넷필터 관련 훅들은 이 후 넷필터 챕터에서 설명한다.
수신한 패킷은 라우팅 서브시스템 탐색을 수행한다. 목적지가 로컬 호스트라면 ip_local_deliver() 함수에 도착할 것이고, 포워딩 될 패킷이면 ip_forward() 함수로 처리될 것이다.
위 다이어그램에서 listified packet은 ip_list_rcv()와 ip_list_rcv_finish() 함수로 처리될 것이다.
IPv4 패킷 수신 핸들러인 ip_rcv() 함수와 ip_list_rcv() 함수는 ip_rcv_core() 함수를 호출하여 IP 수신 루틴을 처리한다.
/*
* Main IP Receive routine.
*/
static struct sk_buff *ip_rcv_core(struct sk_buff *skb, struct net *net)
{
const struct iphdr *iph;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
__IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto out;
}
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
iph = ip_hdr(skb);
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
__IP_ADD_STATS(net,
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto csum_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
__IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
if (pskb_trim_rcsum(skb, len)) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto drop;
}
iph = ip_hdr(skb);
skb->transport_header = skb->network_header + iph->ihl*4;
/* Remove any debris in the socket control block */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
IPCB(skb)->iif = skb->skb_iif;
/* Must drop socket now because of tproxy. */
if (!skb_sk_is_prefetched(skb))
skb_orphan(skb);
return skb;
csum_error:
__IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
inhdr_error:
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NULL;
}
해당 함수에서는 우선 다양한 온전성 검사와 통계 업데이트 및 체크섬 계산을 수행한다.
일부 패딩된 패킷에 대해서는 trim 작업을 수행하기도 한다.
이 후 NF_HOOK 넷필터 훅 함수를 호출한 후, ip_rcv_finish() 혹은 ip_list_rcv_finish() 함수를 호출한다.
해당 함수들은 결국 ip_rcv_finish_core() 함수를 호출하여 수신에 대한 메인 루틴을 처리한다.
static int ip_rcv_finish_core(struct net *net, struct sock *sk,
struct sk_buff *skb, struct net_device *dev,
const struct sk_buff *hint)
{
const struct iphdr *iph = ip_hdr(skb);
int (*edemux)(struct sk_buff *skb);
struct rtable *rt;
int err;
if (ip_can_use_hint(skb, iph, hint)) {
err = ip_route_use_hint(skb, iph->daddr, iph->saddr, iph->tos,
dev, hint);
if (unlikely(err))
goto drop_error;
}
if (net->ipv4.sysctl_ip_early_demux &&
!skb_dst(skb) &&
!skb->sk &&
!ip_is_fragment(iph)) {
const struct net_protocol *ipprot;
int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) {
err = INDIRECT_CALL_2(edemux, tcp_v4_early_demux,
udp_v4_early_demux, skb);
if (unlikely(err))
goto drop_error;
/* must reload iph, skb->head might have changed */
iph = ip_hdr(skb);
}
}
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (!skb_valid_dst(skb)) {
err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, dev);
if (unlikely(err))
goto drop_error;
}
#ifdef CONFIG_IP_ROUTE_CLASSID
if (unlikely(skb_dst(skb)->tclassid)) {
struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
u32 idx = skb_dst(skb)->tclassid;
st[idx&0xFF].o_packets++;
st[idx&0xFF].o_bytes += skb->len;
st[(idx>>16)&0xFF].i_packets++;
st[(idx>>16)&0xFF].i_bytes += skb->len;
}
#endif
if (iph->ihl > 5 && ip_rcv_options(skb, dev))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST ||
skb->pkt_type == PACKET_MULTICAST) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
/* RFC 1122 3.3.6:
*
* When a host sends a datagram to a link-layer broadcast
* address, the IP destination address MUST be a legal IP
* broadcast or IP multicast address.
*
* A host SHOULD silently discard a datagram that is received
* via a link-layer broadcast (see Section 2.4) but does not
* specify an IP multicast or broadcast destination address.
*
* This doesn't explicitly say L2 *broadcast*, but broadcast is
* in a way a form of multicast and the most common use case for
* this is 802.11 protecting against cross-station spoofing (the
* so-called "hole-196" attack) so do it for both.
*/
if (in_dev &&
IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))
goto drop;
}
return NET_RX_SUCCESS;
drop:
kfree_skb(skb);
return NET_RX_DROP;
drop_error:
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
goto drop;
}
라우팅을 위한 작업들을 수행한다. 우선, 라우팅 테이블 lookup 전에 ip_can_use_hint() 함수로 hint 객체 사용 가능 여부와 skb_dst() 함수를 통한 dst 객체 존재 여부를 살펴본다.
dst 객체는 dst_entry 타입 인스턴스로, 라우팅 서브시스템 탐색 결과를 나타낸다.
해당 객체의 주요 멤버로는 int (*input)(struct sk_buff *);와 int (*output)(struct net *net, struct sock *sk, struct sk_buff *skb); 콜백이 있다.
예를 들어, 라우팅 서브시스템 탐색 중에 패킷이 포워딩돼야 하면 input 멤버에 ip_forward() 함수가 설정될 것이며, 로컬 장비를 목적지로 하면 ip_local_deliver() 함수가 설정될 것이다.
사전 작업에 의해 SKB에 적절한 dst 객체를 찾지 못한 경우 ip_route_input_noref() 함수로 라우팅 서브시스템 탐색을 수행한다.
이 후 IPv4 헤더에 옵션이 있다면 ip_rcv_options() 함수로 처리하고, 라우팅 테이블 타입에 따라 통계를 업데이트한다.
이러한 과정들에서 drop될 패킷이라면 ip_rcv_finish_core() 함수는 SKB를 할당 해제하고 NET_RX_DROP를 반환하며, 수신할 패킷이라면 NET_RX_SUCCESS를 반환한다.
ip_rcv_finish_core() 함수가 끝나면 ip_rcv_finish() 함수는 dst_input() 함수를 호출하여 SKB에 연결된 dst 객체의 input 콜백을 호출한다.
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev, NULL);
if (ret != NET_RX_DROP)
ret = dst_input(skb); // input callback 호출
return ret;
}
static void ip_list_rcv_finish(struct net *net, struct sock *sk,
struct list_head *head)
{
struct sk_buff *skb, *next, *hint = NULL;
struct dst_entry *curr_dst = NULL;
struct list_head sublist;
INIT_LIST_HEAD(&sublist);
list_for_each_entry_safe(skb, next, head, list) {
struct net_device *dev = skb->dev;
struct dst_entry *dst;
skb_list_del_init(skb);
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
continue;
if (ip_rcv_finish_core(net, sk, skb, dev, hint) == NET_RX_DROP)
continue;
dst = skb_dst(skb);
if (curr_dst != dst) {
hint = ip_extract_route_hint(net, skb,
((struct rtable *)dst)->rt_type);
/* dispatch old sublist */
if (!list_empty(&sublist))
ip_sublist_rcv_finish(&sublist);
/* start new sublist */
INIT_LIST_HEAD(&sublist);
curr_dst = dst;
}
list_add_tail(&skb->list, &sublist); // 패킷을 sublist에 추가
}
/* dispatch final sublist */
ip_sublist_rcv_finish(&sublist);
}
static void ip_sublist_rcv_finish(struct list_head *head)
{
struct sk_buff *skb, *next;
list_for_each_entry_safe(skb, next, head, list) {
skb_list_del_init(skb);
dst_input(skb); // input callback 호출
}
}
IPv4 멀티캐스트 패킷 수신
ip_rcv_finish_core() 함수에서 라우팅 테이블 lookup을 수행하기 위하여 ip_route_input_noref() 함수를 호출한다고 하였다.
ip_route_input_noref() 함수에서는 RCU lock을 획득하고 다음과 같은 ip_route_input_rcu() 함수를 호출한다.
/* called with rcu_read_lock held */
int ip_route_input_rcu(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev, struct fib_result *res)
{
/* Multicast recognition logic is moved from route cache to here.
* The problem was that too many Ethernet cards have broken/missing
* hardware multicast filters :-( As result the host on multicasting
* network acquires a lot of useless route cache entries, sort of
* SDR messages from all the world. Now we try to get rid of them.
* Really, provided software IP multicast filter is organized
* reasonably (at least, hashed), it does not result in a slowdown
* comparing with route cache reject entries.
* Note, that multicast routers are not affected, because
* route cache entry is created eventually.
*/
if (ipv4_is_multicast(daddr)) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
int our = 0;
int err = -EINVAL;
if (!in_dev)
return err;
our = ip_check_mc_rcu(in_dev, daddr, saddr,
ip_hdr(skb)->protocol);
/* check l3 master if no match yet */
if (!our && netif_is_l3_slave(dev)) {
struct in_device *l3_in_dev;
l3_in_dev = __in_dev_get_rcu(skb->dev);
if (l3_in_dev)
our = ip_check_mc_rcu(l3_in_dev, daddr, saddr,
ip_hdr(skb)->protocol);
}
if (our
#ifdef CONFIG_IP_MROUTE
||
(!ipv4_is_local_multicast(daddr) &&
IN_DEV_MFORWARD(in_dev))
#endif
) {
err = ip_route_input_mc(skb, daddr, saddr,
tos, dev, our);
}
return err;
}
return ip_route_input_slow(skb, daddr, saddr, tos, dev, res);
}
패킷의 목적지 주소(iph->daddr)가 멀티캐스트 주소라면 if문 안의 문장이 실행된다.
멀티캐스트 패킷을 수신하는 것은 로컬 호스트의 주소가 멀티캐스트 그룹에 속하거나 로컬 호스트가 멀티캐스트의 라우터인 경우이다.
로컬 호스트가 멀티캐스트의 라우터인 경우에는 다음과 같이 ip_route_input_mc() 함수를 호출한다.
/* called in rcu_read_lock() section */
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev, int our)
{
struct in_device *in_dev = __in_dev_get_rcu(dev);
unsigned int flags = RTCF_MULTICAST;
struct rtable *rth;
u32 itag = 0;
int err;
err = ip_mc_validate_source(skb, daddr, saddr, tos, dev, in_dev, &itag);
if (err)
return err;
if (our)
flags |= RTCF_LOCAL;
rth = rt_dst_alloc(dev_net(dev)->loopback_dev, flags, RTN_MULTICAST,
IN_DEV_ORCONF(in_dev, NOPOLICY), false);
if (!rth)
return -ENOBUFS;
#ifdef CONFIG_IP_ROUTE_CLASSID
rth->dst.tclassid = itag;
#endif
rth->dst.output = ip_rt_bug;
rth->rt_is_input= 1;
#ifdef CONFIG_IP_MROUTE
if (!ipv4_is_local_multicast(daddr) && IN_DEV_MFORWARD(in_dev))
rth->dst.input = ip_mr_input;
#endif
RT_CACHE_STAT_INC(in_slow_mc);
skb_dst_set(skb, &rth->dst);
return 0;
}
로컬 호스트가 멀티캐스트 라우터이고 IN_DEV_MFORWARD(in_indev)가 설정돼 있다면 dst의 input 콜백은 ip_mr_input()으로 설정된다. ip_mr_input() 함수는 멀티캐스트 패킷 포워딩을 위한 함수로, MFC(Multicast Forwarding Cache)라는 자료구조에서 유효한 항목이 발견되면 ip_mr_forward() 함수를 호출한다.
int ip_mr_input(struct sk_buff *skb)
{
...
/* already under rcu_read_lock() */
cache = ipmr_cache_find(mrt, ip_hdr(skb)->saddr, ip_hdr(skb)->daddr);
...
/* No usable cache entry */
if (!cache) {
...
kfree_skb(skb);
return -ENODEV;
}
read_lock(&mrt_lock);
ip_mr_forward(net, mrt, dev, skb, cache, local);
read_unlock(&mrt_lock);
}
ip_mr_forward() 함수에서는 여러 검사를 통해 필요한 데이터들을 결정하여 ipmr_queue_xmit() 함수를 호출한다.
static void ipmr_queue_xmit(struct net *net, struct mr_table *mrt,
int in_vifi, struct sk_buff *skb, int vifi)
{
...
vif->pkt_out++;
vif->bytes_out += skb->len;
skb_dst_drop(skb);
skb_dst_set(skb, &rt->dst);
ip_decrease_ttl(ip_hdr(skb));
/* FIXME: forward and output firewalls used to be called here.
* What do we do with netfilter? -- RR
*/
if (vif->flags & VIFF_TUNNEL) {
ip_encap(net, skb, vif->local, vif->remote);
/* FIXME: extra output firewall step used to be here. --RR */
vif->dev->stats.tx_packets++;
vif->dev->stats.tx_bytes += skb->len;
}
IPCB(skb)->flags |= IPSKB_FORWARDED;
/* RFC1584 teaches, that DVMRP/PIM router must deliver packets locally
* not only before forwarding, but after forwarding on all output
* interfaces. It is clear, if mrouter runs a multicasting
* program, it should receive packets not depending to what interface
* program is joined.
* If we will not make it, the program will have to join on all
* interfaces. On the other hand, multihoming host (or router, but
* not mrouter) cannot join to more than one interface - it will
* result in receiving multiple packets.
*/
NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
net, NULL, skb, skb->dev, dev,
ipmr_forward_finish);
return;
out_free:
kfree_skb(skb);
}
위와 같이 TTL 값을 1 감소한 후 ipmr_forward_finish() 함수를 호출한다.
static inline int ipmr_forward_finish(struct net *net, struct sock *sk,
struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
IP_INC_STATS(net, IPSTATS_MIB_OUTFORWDATAGRAMS);
IP_ADD_STATS(net, IPSTATS_MIB_OUTOCTETS, skb->len);
if (unlikely(opt->optlen))
ip_forward_options(skb);
return dst_output(net, sk, skb);
}
ipmr_forward_finish() 함수에서는 결국 dst_output 함수를 통해 SKB에 등록된 output callback을 호출한다.
IPv4 패킷 송신
IPv4 계층에서는 Transport Layer에서 Datalink Layer로 패킷을 전달하는 수단을 제공한다.
TCPv4 같이 자체적으로 단편화를 처리하는 전송 프로토콜에서는 ip_queue_xmit() 함수로 SKB를 전달한다.
(handshake 과정에서는 ip_build_and_send_pkt 함수를 사용하기도 한다.)
UDPv4, ICMPv4, RAW Socket과 같이 단편화 처리를 하지 않는 프로토콜에는 ip_append_data() 함수로 SKB를 전달한다.
ip_append_data() 함수의 경우 단순히 socket에 패킷을 추가하고, 실제로 전송은 추후에 ip_flush_pending_frames() 함수나 ip_push_pending_frames() 함수가 처리한다.
IPv4 패킷 송신 Flow를 간단하게 도식화하면 다음과 같다.
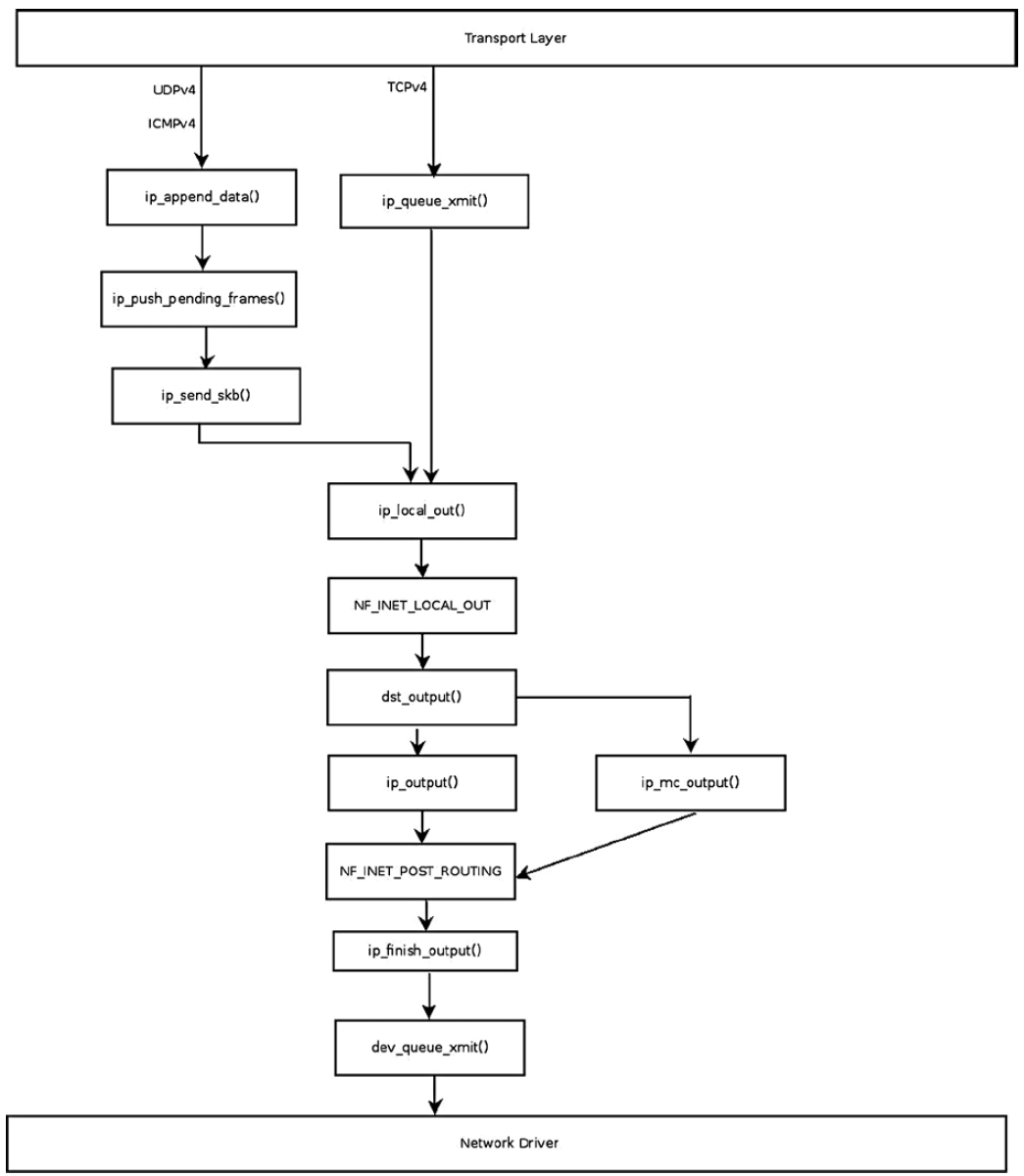 다이어그램은 개념적인 것으로, ip_append_data() 함수가 직접 ip_push_pending_frames() 함수를 호출하지는 않는다는 것을 명심한다.
다이어그램은 개념적인 것으로, ip_append_data() 함수가 직접 ip_push_pending_frames() 함수를 호출하지는 않는다는 것을 명심한다.
추후 UDPv4 챕터에서 설명하겠지만, corking 기능으로 인하여 단일 데이터그램에 pending 되어 있는 패킷은 ip_flush_pending_frames()를 호출하여 전송을 시작한다.
corking 기능을 사용하지 않는 경우엔 ip_make_skb() 함수를 통해 패킷을 송신하는데, 이는 ip_append_data와 ip_flush_pending_frames 함수를 합친 것과 같다.
이 외에도 일부 경우에는 dst_output() 함수를 직접 호출하는 경우가 있다.
우선 ip_queue_xmit() 함수의 정의는 다음과 같다.
/* Note: skb->sk can be different from sk, in case of tunnels */
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
no_route:
rcu_read_unlock();
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
kfree_skb(skb);
return -EHOSTUNREACH;
}
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl)
{
return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos);
}
우선 skb_rtable() 함수와 __sk_dst_check() 함수로 이미 라우팅 경로를 찾은 패킷인지 확인한다.
아니라면 ip_route_output_ports() 함수로 라우팅 서브시스템 lookup을 수행한다.
라우팅 테이블 탐색에 실패하거나 strictroute 플래그와 rt_uses_gateway 플래그가 설정되어 있다면 패킷은 drop된다.
이 후 IPv4 헤더를 만든다. 현재 skb->data가 TCPv4 헤더를 가리키고 있기 때문에, skb_push() 함수로 IPv4 헤더의 크기 만큼 skb->data 포인터를 뒤로 이동시킨다.
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4); // 주소 설정
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) { // IP 옵션 헤더 설정
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1); // id 설정
헤더 설정이 완료되었으면 ip_local_out() 함수를 호출하여 패킷을 전송한다.
ip_append_data() 함수는 다음과 같다.
/*
* ip_append_data() and ip_append_page() can make one large IP datagram
* from many pieces of data. Each pieces will be holded on the socket
* until ip_push_pending_frames() is called. Each piece can be a page
* or non-page data.
*
* Not only UDP, other transport protocols - e.g. raw sockets - can use
* this interface potentially.
*
* LATER: length must be adjusted by pad at tail, when it is required.
*/
int ip_append_data(struct sock *sk, struct flowi4 *fl4,
int getfrag(void *from, char *to, int offset, int len,
int odd, struct sk_buff *skb),
void *from, int length, int transhdrlen,
struct ipcm_cookie *ipc, struct rtable **rtp,
unsigned int flags)
{
struct inet_sock *inet = inet_sk(sk);
int err;
if (flags&MSG_PROBE)
return 0;
if (skb_queue_empty(&sk->sk_write_queue)) {
err = ip_setup_cork(sk, &inet->cork.base, ipc, rtp);
if (err)
return err;
} else {
transhdrlen = 0;
}
return __ip_append_data(sk, fl4, &sk->sk_write_queue, &inet->cork.base,
sk_page_frag(sk), getfrag,
from, length, transhdrlen, flags);
}
MSG_PROBE 플래그가 설정되어 있다면 호출자가 일부 정보(보통 MTU)에만 관심이 있다는 의미이므로 굳이 패킷을 전송할 필요 없이 0을 반환한다.
transhdrlen 값은 단편화 패킷의 첫 번째 패킷 여부를 확인하는 데 사용된다.
ip_setup_cork() 함수는 cork IP 옵션 객체가 없을 경우 이를 생성하고, 지정된 ipcm_cookie 객체의 IP 옵션을 복사한다.
실제 작업은 __ip_append_data() 함수에서 수행한다.
해당 함수에서는 fragment 길이를 계산하여 chained skb를 만들고, 각 fragment들에 적절한 header 설정을 한다. 설정이 완료되면 __skb_queue_tail() 함수로 패킷을 pending queue에 추가한다.
Fragmentation
NIC에서는 패킷의 크기를 MTU로 제한한다. 일반적인 이더넷 네트워크에서 MTU는 1500 바이트이다.
송신 NIC의 MTU보다 큰 패킷을 보낼 경우 패킷을 조각으로 나눠야 한다.
해당 작업을 수행하는 ip_fragment() 함수의 정의는 다음과 같다.
static int ip_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
unsigned int mtu,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
struct iphdr *iph = ip_hdr(skb);
if ((iph->frag_off & htons(IP_DF)) == 0)
return ip_do_fragment(net, sk, skb, output);
if (unlikely(!skb->ignore_df ||
(IPCB(skb)->frag_max_size &&
IPCB(skb)->frag_max_size > mtu))) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
kfree_skb(skb);
return -EMSGSIZE;
}
return ip_do_fragment(net, sk, skb, output);
}
매개변수 output는 전송에 사용할 콜백 함수이다. ip_fragment() 함수가 __ip_finish_output() 함수나 ip_finish_output_gso()에서 호출되면 output 함수는 ip_finish_output2()가 된다.
헤더의 frag_off 필드에 IP_DF (Don’t Fragment) 플래그가 설정되어 있지 않다면 바로 ip_do_fragment()를 호출한다.
IP_DF가 설정되어 있는 경우(단편화가 허용되지 않는 경우) fragment의 사이즈가 MTU보다 크다면 ICMP_DEST_UNREACH/ICMP_FRAG_NEEDED ICMP 메시지를 송신자에게 회신하고, 패킷을 폐기한다.
그 외의 경우엔 ip_do_fragment() 함수를 호출한다. ip_do_fragment() 함수의 정의는 다음과 같다.
/*
* This IP datagram is too large to be sent in one piece. Break it up into
* smaller pieces (each of size equal to IP header plus
* a block of the data of the original IP data part) that will yet fit in a
* single device frame, and queue such a frame for sending.
*/
int ip_do_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
struct iphdr *iph;
struct sk_buff *skb2;
struct rtable *rt = skb_rtable(skb);
unsigned int mtu, hlen, ll_rs;
struct ip_fraglist_iter iter;
ktime_t tstamp = skb->tstamp;
struct ip_frag_state state;
int err = 0;
/* for offloaded checksums cleanup checksum before fragmentation */
if (skb->ip_summed == CHECKSUM_PARTIAL &&
(err = skb_checksum_help(skb)))
goto fail;
/*
* Point into the IP datagram header.
*/
iph = ip_hdr(skb);
mtu = ip_skb_dst_mtu(sk, skb);
if (IPCB(skb)->frag_max_size && IPCB(skb)->frag_max_size < mtu)
mtu = IPCB(skb)->frag_max_size;
/*
* Setup starting values.
*/
hlen = iph->ihl * 4;
mtu = mtu - hlen; /* Size of data space */
IPCB(skb)->flags |= IPSKB_FRAG_COMPLETE;
ll_rs = LL_RESERVED_SPACE(rt->dst.dev);
/* When frag_list is given, use it. First, check its validity:
* some transformers could create wrong frag_list or break existing
* one, it is not prohibited. In this case fall back to copying.
*
* LATER: this step can be merged to real generation of fragments,
* we can switch to copy when see the first bad fragment.
*/
if (skb_has_frag_list(skb)) {
struct sk_buff *frag, *frag2;
unsigned int first_len = skb_pagelen(skb);
if (first_len - hlen > mtu ||
((first_len - hlen) & 7) ||
ip_is_fragment(iph) ||
skb_cloned(skb) ||
skb_headroom(skb) < ll_rs)
goto slow_path;
skb_walk_frags(skb, frag) {
/* Correct geometry. */
if (frag->len > mtu ||
((frag->len & 7) && frag->next) ||
skb_headroom(frag) < hlen + ll_rs)
goto slow_path_clean;
/* Partially cloned skb? */
if (skb_shared(frag))
goto slow_path_clean;
BUG_ON(frag->sk);
if (skb->sk) {
frag->sk = skb->sk;
frag->destructor = sock_wfree;
}
skb->truesize -= frag->truesize;
}
/* Everything is OK. Generate! */
ip_fraglist_init(skb, iph, hlen, &iter);
for (;;) {
/* Prepare header of the next frame,
* before previous one went down. */
if (iter.frag) {
ip_fraglist_ipcb_prepare(skb, &iter);
ip_fraglist_prepare(skb, &iter);
}
skb->tstamp = tstamp;
err = output(net, sk, skb);
if (!err)
IP_INC_STATS(net, IPSTATS_MIB_FRAGCREATES);
if (err || !iter.frag)
break;
skb = ip_fraglist_next(&iter);
}
if (err == 0) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGOKS);
return 0;
}
kfree_skb_list(iter.frag);
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
return err;
slow_path_clean:
skb_walk_frags(skb, frag2) {
if (frag2 == frag)
break;
frag2->sk = NULL;
frag2->destructor = NULL;
skb->truesize += frag2->truesize;
}
}
slow_path:
/*
* Fragment the datagram.
*/
ip_frag_init(skb, hlen, ll_rs, mtu, IPCB(skb)->flags & IPSKB_FRAG_PMTU,
&state);
/*
* Keep copying data until we run out.
*/
while (state.left > 0) {
bool first_frag = (state.offset == 0);
skb2 = ip_frag_next(skb, &state);
if (IS_ERR(skb2)) {
err = PTR_ERR(skb2);
goto fail;
}
ip_frag_ipcb(skb, skb2, first_frag, &state);
/*
* Put this fragment into the sending queue.
*/
skb2->tstamp = tstamp;
err = output(net, sk, skb2);
if (err)
goto fail;
IP_INC_STATS(net, IPSTATS_MIB_FRAGCREATES);
}
consume_skb(skb);
IP_INC_STATS(net, IPSTATS_MIB_FRAGOKS);
return err;
fail:
kfree_skb(skb);
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
return err;
}
ip_do_fragment() 함수에는 fast path와 slow path가 있다.
SKB의 frag_list가 NULL이 아닌 경우엔 fast path로 진입하고, NULL인 경우엔 slow path로 진입한다.
Fast Path
SKB에 frag_list가 있는 경우 유효성 검사를 진행하고 frag_list를 사용한다.
일부 잘못된 frag_list를 생성하거나 기존 frag_list가 손상된 경우 slow path로 대체된다.
frag_list가 유효한 경우 단편화에 대한 IPv4 헤더가 만들어진다.
int ip_do_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
...
/* Everything is OK. Generate! */
ip_fraglist_init(skb, iph, hlen, &iter);
...
}
void ip_fraglist_init(struct sk_buff *skb, struct iphdr *iph,
unsigned int hlen, struct ip_fraglist_iter *iter)
{
unsigned int first_len = skb_pagelen(skb);
iter->frag = skb_shinfo(skb)->frag_list;
skb_frag_list_init(skb);
iter->offset = 0;
iter->iph = iph;
iter->hlen = hlen;
skb->data_len = first_len - skb_headlen(skb);
skb->len = first_len;
iph->tot_len = htons(first_len);
iph->frag_off = htons(IP_MF);
ip_send_check(iph);
}
첫 번째 fragment 헤더에는 frag_off에 IP_MF 플래그가 설정된다. 이는 단편화된 패킷이 더 있다는 의미이다.
ip_send_check() 함수는 헤더의 필드값이 바뀐 후 체크섬을 새로 계산하는 함수이다.
이 후 마지막 fragment를 제외한 모든 fragment의 헤더에는 IP_MF 플래그가 설정되고, frag_off의 하위 13비트에 단편화 offset이 설정된다.
마지막 fragment 패킷은 IP_MF 플래그가 설정되지 않지만 하위 13비트는 여전히 단편화 offset을 담고 있어야 한다.
첫 번째 헤더 생성 이후의 루틴은 다음과 같다.
int ip_do_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
...
for (;;) {
/* Prepare header of the next frame,
* before previous one went down. */
if (iter.frag) {
ip_fraglist_ipcb_prepare(skb, &iter);
ip_fraglist_prepare(skb, &iter);
}
skb->tstamp = tstamp;
err = output(net, sk, skb);
if (!err)
IP_INC_STATS(net, IPSTATS_MIB_FRAGCREATES);
if (err || !iter.frag)
break;
skb = ip_fraglist_next(&iter);
}
...
}
작업 순서는 다음과 같다.
- ip_fraglist_prepare() 함수로 다음 프레임의 헤더 준비
- 현재 프레임을 output() 함수로 전송
- output 결과가 정상이라면 IPSTATS_MIB_FRAGCREATES 통계 증가
- output 결과가 비정상이라면 반복문을 빠져나와 IPSTATS_MIB_FRAGFAILS 통계 증가
- 마지막 output의 결과가 정상이라면 IPSTATS_MIB_FRAGOKS 통계 증가
- ip_fraglist_next() 함수로 skb를 다음 프레임으로 교체
여기서 인자로 전달되는 iter는 다음 fragment를 가지고 있는 ip_fraglist_iter 객체이다.
ip_fraglist_prepare() 함수와 ip_fraglist_next() 함수는 다음과 같다.
void ip_fraglist_prepare(struct sk_buff *skb, struct ip_fraglist_iter *iter)
{
unsigned int hlen = iter->hlen;
struct iphdr *iph = iter->iph;
struct sk_buff *frag;
frag = iter->frag;
frag->ip_summed = CHECKSUM_NONE;
skb_reset_transport_header(frag);
__skb_push(frag, hlen); // skb->data 포인터가 IPv4 헤더를 가리키도록 옮긴다.
skb_reset_network_header(frag); // skb->network_header가 수정된 skb->data를 가리키게 한다.
memcpy(skb_network_header(frag), iph, hlen); // 생성된 IPv4 헤더를 network 헤더로 복사한다.
iter->iph = ip_hdr(frag); // 다음 fragment 헤더를 설정한다.
iph = iter->iph;
iph->tot_len = htons(frag->len); // 다음 fragment 헤더의 tot_len을 초기화한다.
ip_copy_metadata(frag, skb); // SKB의 메타데이터를 frag에 복사한다.
iter->offset += skb->len - hlen; // 다음 fragment의 offset을 계산한다.
iph->frag_off = htons(iter->offset >> 3); // frag_off 필드는 8바이트 배수로 계산되므로 8을 나눈다.
if (frag->next) // 마지막 fragment를 제외한 fragment에 IP_MF 플래그를 설정한다.
iph->frag_off |= htons(IP_MF);
/* Ready, complete checksum */
ip_send_check(iph); // checksum을 재계산한다.
}
static inline struct sk_buff *ip_fraglist_next(struct ip_fraglist_iter *iter)
{
struct sk_buff *skb = iter->frag; // 다음 fragment를 가져온다.
iter->frag = skb->next; // iter->frag에 그 다음 fragment를 설정한다.
skb_mark_not_on_list(skb);
return skb; // skb를 반환한다.
}
Slow Path
slow path의 구현은 다음과 같다.
int ip_do_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
slow_path:
/*
* Fragment the datagram.
*/
ip_frag_init(skb, hlen, ll_rs, mtu, IPCB(skb)->flags & IPSKB_FRAG_PMTU,
&state);
/*
* Keep copying data until we run out.
*/
while (state.left > 0) {
bool first_frag = (state.offset == 0);
skb2 = ip_frag_next(skb, &state);
if (IS_ERR(skb2)) {
err = PTR_ERR(skb2);
goto fail;
}
ip_frag_ipcb(skb, skb2, first_frag, &state);
/*
* Put this fragment into the sending queue.
*/
skb2->tstamp = tstamp;
err = output(net, sk, skb2);
if (err)
goto fail;
IP_INC_STATS(net, IPSTATS_MIB_FRAGCREATES);
}
consume_skb(skb);
IP_INC_STATS(net, IPSTATS_MIB_FRAGOKS);
return err;
}
- ip_frag_init() 함수로 첫 번째 fragment를 준비한다.
- state.left가 0보다 큰 동안 (단편화해야 할 내용이 남아 있는 동안) 루틴을 반복한다.
- ip_frag_next() 함수로 다음 fragment를 준비한다.
- output 함수로 fragment를 전송한다.
- 통계를 업데이트한다.
여기서 핵심은 ip_frag_next() 함수이다.
해당 함수에서는 새로운 SKB를 할당하고, 기존 SKB로부터 다양한 메타데이터를 복사한다.
마지막 fragment가 아니라면 IP_MF 플래그를 설정하고, 헤더와 state의 길이 및 오프셋을 계산하고 체크섬을 계산한다.
Defragmentation
단편화된 패킷은 이 후 역단편화를 통해 원본 패킷으로 재조립되어야 한다.
재조립되는 패킷은 IPv4 헤더의 같은 id를 가지고 하나의 버퍼에 담긴다.
역단편화는 ip_defrag() 함수가 수행하며, 호출되는 곳은 다음과 같다.
- ip_local_deliver() 함수
- 세 번째 인자 값이 IP_DEFRAG_LOCAL_DELIVER
- ip_call_ra_chain() 함수
- 세 번째 인자 값이 IP_DEFRAG_CALL_RA_CHAIN
그 외에 IPVS 같은 곳에서 호출되기도 하는데, 세 번째 인자를 통해 호출된 곳을 식별할 수 있다. 패킷이 단편화되어있는지 여부는 ip_is_fragment() 함수로 판단하는데, 정의는 다음과 같다.
// IP_MF 플래그가 설정되어 있거나 frag_off 값이 0이 아니면 true
static inline bool ip_is_fragment(const struct iphdr *iph)
{
return (iph->frag_off & htons(IP_MF | IP_OFFSET)) != 0;
}
단편화된 패킷은 다음과 같기 때문에 위 함수는 모든 단편화 패킷에 대해 true를 반환한다.
- 첫번째 fragment에는 IP_MF가 설정되어 있다.
- 마지막 fragment는 frag_off가 0이 아니다.
- 다른 모든 fragment는 IP_MF가 설정되어 있고 frag_off도 0이 아니다.
역단편화는 ipq 객체의 inet_frag_queue 멤버를 토대로 진행한다.
inet_frag_queue 객체의 멤버 compare_key를 해싱하여 fragment를 식별한다.
해시에 사용되는 compare_key는 출발지 주소, 목적지 주소, 패킷 id, 프로토콜, user, vif 필드로 구성되어 있다.
/* Describe an entry in the "incomplete datagrams" queue. */
struct ipq {
struct inet_frag_queue q;
u8 ecn; /* RFC3168 support */
u16 max_df_size; /* largest frag with DF set seen */
int iif;
unsigned int rid;
struct inet_peer *peer;
};
/**
* struct inet_frag_queue - fragment queue
*
* @node: rhash node
* @key: keys identifying this frag.
* @timer: queue expiration timer
* @lock: spinlock protecting this frag
* @refcnt: reference count of the queue
* @rb_fragments: received fragments rb-tree root
* @fragments_tail: received fragments tail
* @last_run_head: the head of the last "run". see ip_fragment.c
* @stamp: timestamp of the last received fragment
* @len: total length of the original datagram
* @meat: length of received fragments so far
* @flags: fragment queue flags
* @max_size: maximum received fragment size
* @fqdir: pointer to struct fqdir
* @rcu: rcu head for freeing deferall
*/
struct inet_frag_queue {
struct rhash_head node;
union {
struct frag_v4_compare_key v4;
struct frag_v6_compare_key v6;
} key;
struct timer_list timer;
spinlock_t lock;
refcount_t refcnt;
struct rb_root rb_fragments;
struct sk_buff *fragments_tail;
struct sk_buff *last_run_head;
ktime_t stamp;
int len;
int meat;
__u8 flags;
u16 max_size;
struct fqdir *fqdir;
struct rcu_head rcu;
};
struct frag_v4_compare_key {
__be32 saddr;
__be32 daddr;
u32 user;
u32 vif;
__be16 id;
u16 protocol;
};
static u32 ip4_key_hashfn(const void *data, u32 len, u32 seed)
{
return jhash2(data,
sizeof(struct frag_v4_compare_key) / sizeof(u32), seed);
}
ip_defrag() 함수의 정의는 다음과 같다.
/* Process an incoming IP datagram fragment. */
int ip_defrag(struct net *net, struct sk_buff *skb, u32 user)
{
struct net_device *dev = skb->dev ? : skb_dst(skb)->dev;
int vif = l3mdev_master_ifindex_rcu(dev);
struct ipq *qp;
__IP_INC_STATS(net, IPSTATS_MIB_REASMREQDS);
skb_orphan(skb);
/* Lookup (or create) queue header */
qp = ip_find(net, ip_hdr(skb), user, vif);
if (qp) {
int ret;
spin_lock(&qp->q.lock);
ret = ip_frag_queue(qp, skb);
spin_unlock(&qp->q.lock);
ipq_put(qp);
return ret;
}
__IP_INC_STATS(net, IPSTATS_MIB_REASMFAILS);
kfree_skb(skb);
return -ENOMEM;
}
- ip_find() 함수로 SKB의 ipq를 찾고, 없다면 ipq 객체를 생성한다.
- ip_frag_queue() 함수로 단편화된 패킷의 연결 리스트에 단편화된 패킷을 추가한다.
- 역단편화가 완료되면 ip_frag_queue() 함수가 ip_frag_reasm() 함수를 호출한다.
- ip_frag_reasm() 함수는 ipq_kill() 함수를 호출하여 타이머를 중지한다. 이 후 inet_frag_reasm_prepare() 함수와 inet_frag_reasm_finish() 함수를 호출하여 재조립을 완료한다.
- 타이머가 초과하면 ip_expire() 함수가 ICMP_TIME_EXCEEDED/ICMP_EXC_FRAGTIME icmp 메시지를 송신한다.
Forwarding
포워딩에 관한 내용은 이 전 송수신 단계에서 간단하게 살펴봤다.
포워딩을 처리하는 함수 ip_forward()와 ip_forward_finish() 함수의 정의는 다음과 같다.
static int ip_forward_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
__IP_INC_STATS(net, IPSTATS_MIB_OUTFORWDATAGRAMS);
__IP_ADD_STATS(net, IPSTATS_MIB_OUTOCTETS, skb->len);
#ifdef CONFIG_NET_SWITCHDEV
if (skb->offload_l3_fwd_mark) {
consume_skb(skb);
return 0;
}
#endif
if (unlikely(opt->optlen))
ip_forward_options(skb);
skb->tstamp = 0;
return dst_output(net, sk, skb);
}
int ip_forward(struct sk_buff *skb)
{
u32 mtu;
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
struct net *net;
/* that should never happen */
if (skb->pkt_type != PACKET_HOST)
goto drop;
if (unlikely(skb->sk))
goto drop;
if (skb_warn_if_lro(skb))
goto drop;
if (!xfrm4_policy_check(NULL, XFRM_POLICY_FWD, skb))
goto drop;
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb))
return NET_RX_SUCCESS;
skb_forward_csum(skb);
net = dev_net(skb->dev);
/*
* According to the RFC, we must first decrease the TTL field. If
* that reaches zero, we must reply an ICMP control message telling
* that the packet's lifetime expired.
*/
if (ip_hdr(skb)->ttl <= 1)
goto too_many_hops;
if (!xfrm4_route_forward(skb))
goto drop;
rt = skb_rtable(skb);
if (opt->is_strictroute && rt->rt_uses_gateway)
goto sr_failed;
IPCB(skb)->flags |= IPSKB_FORWARDED;
mtu = ip_dst_mtu_maybe_forward(&rt->dst, true);
if (ip_exceeds_mtu(skb, mtu)) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
goto drop;
}
/* We are about to mangle packet. Copy it! */
if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len))
goto drop;
iph = ip_hdr(skb);
/* Decrease ttl after skb cow done */
ip_decrease_ttl(iph);
/*
* We now generate an ICMP HOST REDIRECT giving the route
* we calculated.
*/
if (IPCB(skb)->flags & IPSKB_DOREDIRECT && !opt->srr &&
!skb_sec_path(skb))
ip_rt_send_redirect(skb);
if (net->ipv4.sysctl_ip_fwd_update_priority)
skb->priority = rt_tos2priority(iph->tos);
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
net, NULL, skb, skb->dev, rt->dst.dev,
ip_forward_finish);
sr_failed:
/*
* Strict routing permits no gatewaying
*/
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
too_many_hops:
/* Tell the sender its packet died... */
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
LRO(Large Receive Offload)는 패킷을 상위 네트워크 계층으로 전달하기 전에 병합해 하나의 큰 SKB로 만들어 CPU 부하를 줄이는 최적화 기법이다.
LRO 패킷의 경우 상위 네트워크 계층으로 전달하기 위함이므로 포워딩을 고려하지 않는다. 당연히 SKB의 크기 또한 MTU보다 클 것이므로 포워딩 과정에서 해당 패킷은 drop된다.
router_alert option이 설정돼 있다면 패킷을 처리하기 위하여 ip_call_ra_chain() 함수가 호출된다.
RAW socket에서 IP_ROUTER_ALERT를 지정하면 socket이 ip_ra_chain 리스트에 추가된다.
ip_call_ra_chain() 함수에서는 ip_ra_chain 리스트에 있는 모든 socket에 패킷을 전달한다.
RAW socket은 따로 리스닝하는 port가 없기 때문에 수신할 특정 socket을 지정할 수 없기 때문에 모든 socket에 전달해야 한다.
이 후 포워딩 과정은 다음과 같다.
- 라우팅 테이블에서 경로를 찾는다.
- strictroute option과 rt_uses_gateway 플래그가 설정되어 있다면 ICMP_DEST_UNREACH/ICMP_SR_FAILED ICMP 메시지를 회신하고 패킷을 drop한다.
- SKB가 MTU를 초과하면 ICMP_DEST_UNREACH/ICMP_FRAG_NEEDED ICMP 메시지를 회신하고 패킷을 drop한다.
- SKB의 사본을 저장하고 TTL을 1 감소시킨다.
- IPSKB_DOREDIRECT 플래그가 설정되어 있다면 ip_rt_send_redirect() 함수를 호출한다.
- SKB의 우선순위를 계산한 후, 넷필터 HOOK을 호출하고 ip_forward_finish() 함수에 진입한다.
- ip_forward_finish() 함수에서는 IPv4 Option이 있다면 ip_forward_options() 함수를 호출한다.
- dst_output() 함수를 호출하여 output callback 함수를 호출한다.
예제
예제의 내용은 이 전 ICMPv4 포스트의 예제에 이어서 진행한다.
linux/net/ipv4/ip_km.h
다음과 같은 두 라인을 추가한다
#define KM_DEBUG_IP_SND 18
#define MANI_ADDR 168430212
/*
* saddr를 조작할 address로, 위 값은 10.10.10.132 의 정수 값이다.
* 10.10.10.132는 16진수로 0a0a0a84 이고,
* a0a0a84를 10진수로 하면 168430212 이다.
* 0x 접두사를 붙여서 16진수 주소 그대로 적어도 상관없다.
* 예를 들어 조작할 saddr이 10.1.1.100 이라면
* 0xa010164 로 적으면 된다.
*/
MANI_ADDR 매크로 명과 주소 값은 원하는 대로 설정한다.
linux/net/ipv4/ip_output.c
헤더 파일을 삽입한다.
#include "ip_km.h"
__ip_queue_xmit() 함수의 ip_copy_addrs() 함수 다음 라인에 내용을 추가한다.
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
...
ip_copy_addrs(iph, fl4);
// 518 라인
if (km_debug_state == KM_DEBUG_IP_SND) {
iph->saddr = htonl(MANI_ADDR);
}
}
__ip_queue_xmit() 함수는 TCPv4 계층에서 사용하므로, TCP 프로토콜의 Tx 패킷 source ip address가 10.10.10.132로 변화할 것이다.
빌드 및 결과
linux root 디렉토리에서 다음과 같이 빌드한다.
$ make -j8
$ sudo make install
재부팅 후 호스트 머신에서 wireshark로 가상머신의 NIC를 캡처하면 다음과 같다.
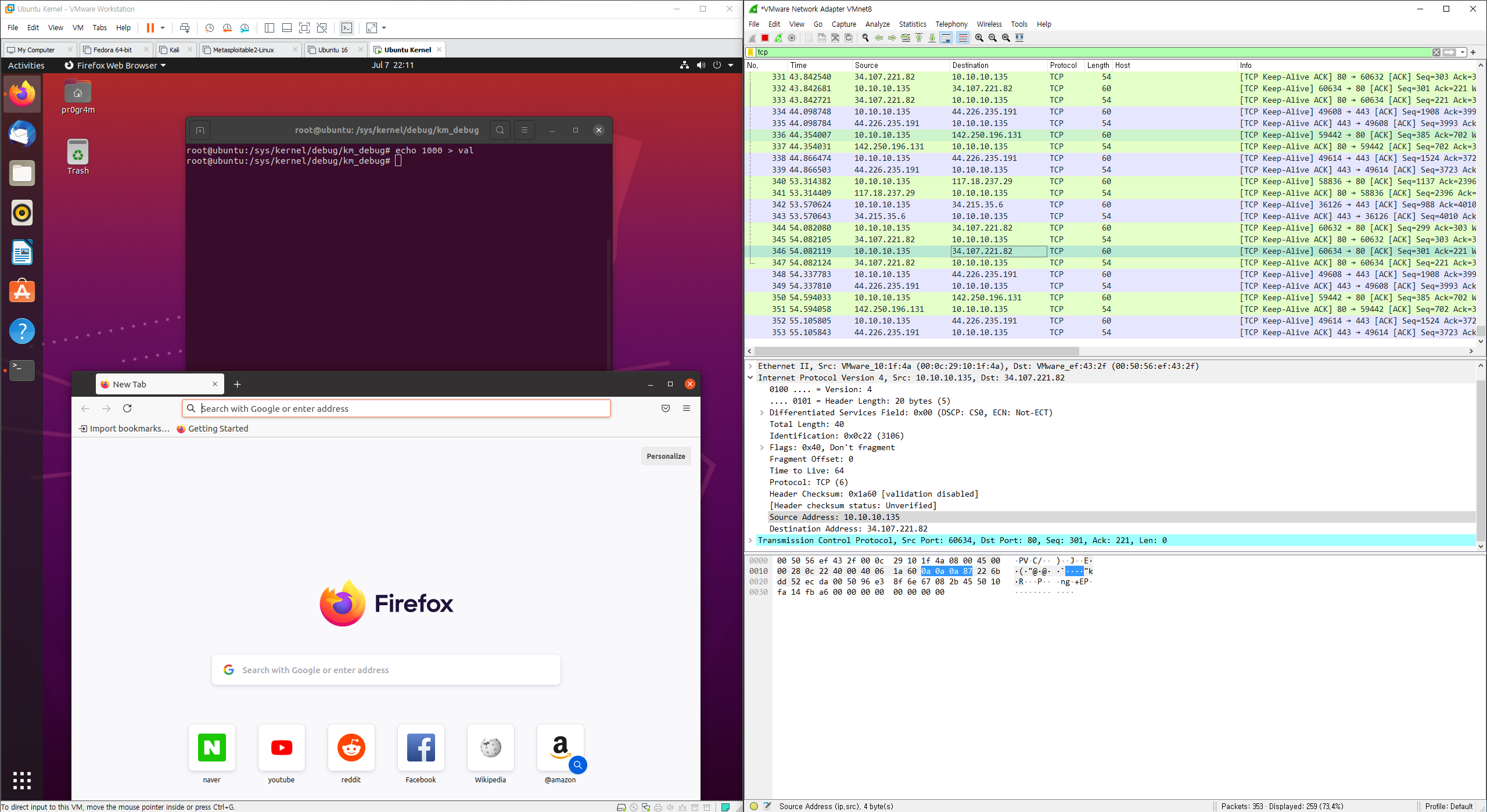
아직 변조가 시작되지 않은 상태로, source ip address가 10.10.10.135이다.
변조를 위해 다음과 같이 km_debug_state 값을 18로 수정한다.
# root 계정으로 작업해야 함
$ echo 18 > /sys/kernel/debug/km_debug/val
수정 후 캡처 내용을 보면 source ip address가 10.10.10.132로 변경하는 것을 볼 수 있다.